Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
O Copilot Studio permite-lhe melhorar os seus agentes com conhecimento específico do domínio, alimentado pelas mesmas origens de dados fidedignas e familiares que já tem vindo a criar através dos conectores do Power Platform.
Ao carregar conteúdo externo do seu dispositivo, OneDrive ou SharePoint, pode melhorar os seus agentes com conhecimento contextual personalizado para o seu negócio. Estes ficheiros são armazenados em segurança no Microsoft Dataverse e processados automaticamente em índices semânticos e incorporações vetoriais. Esta configuração permite que os seus agentes gerem respostas mais precisas e fundamentadas com base nas informações fornecidas.
Os ficheiros carregados no Copilot Studio utilizam o Microsoft Dataverse para ingerir ficheiros sem formato e criar índices e incorporações vetoriais que ajudam a fornecer respostas de qualidade aos seus agentes. Estes ficheiros podem ser carregados a partir do seu computador ou ligando-se ao OneDrive ou SharePoint.
O carregamento de ficheiros como fontes de conhecimento ajuda os criadores a melhorar os seus agentes com dados adicionais, alargando o conhecimento do modelo de linguagem e fundamentando o agente em informação específica fornecida pelo criador. Os criadores podem carregar diversos ficheiros que são indexados semanticamente como vetores incorporados e depois utilizados como conhecimento para os agentes. Este conhecimento utilizado nos agentes pode depois ser partilhado com utilizadores autenticados e não autenticados do agente.
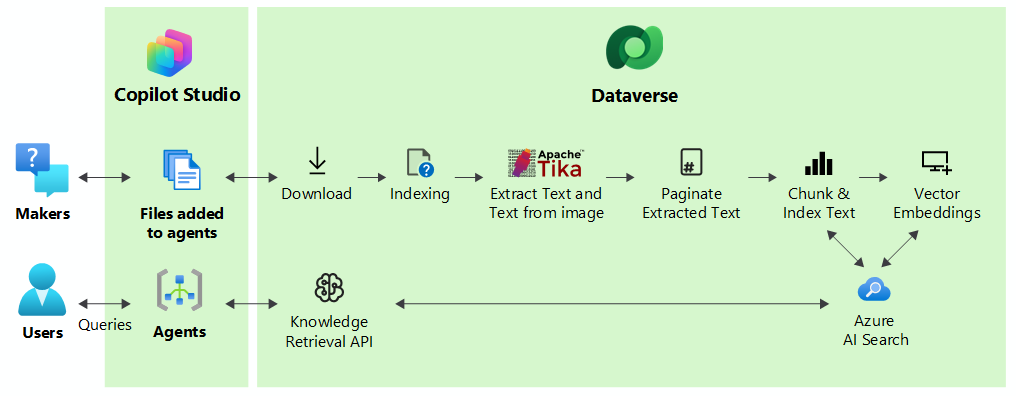
Para melhorar as respostas do agente, os ficheiros carregados são divididos em partes para um processamento mais rápido e indexados por vetor para fornecer correspondências semânticas com a consulta do utilizador. Os ficheiros são armazenados de forma segura no Dataverse. Quando um utilizador realiza uma consulta através de um agente, o Copilot Studio encontra os segmentos mais relevantes que correspondem à intenção da consulta do utilizador e devolve-lhe os resultados.
Da mesma forma, o Dataverse ingere ficheiros do OneDrive, ficheiros do SharePoint (utilizando as opções em carregamento de ficheiros) e conteúdo não estruturado, como artigos da base de dados de conhecimento de outros sistemas empresariais, como o Salesforce, ServiceNow, Confluence e ZenDesk, para fornecer melhores resultados semânticos para o agente.
Nota
Para mais informações sobre a utilização de dados estruturados, consulte Utilizar um interpretador de código para analisar dados estruturados.
Conectores do Power Platform para dados não estruturados
Os seguintes conectores do Power Platform estão configurados para funcionar com origens de dados não estruturadas:
OneDrive
O OneDrive permite que os criadores utilizem uma interface de seleção de ficheiros para escolher os ficheiros e pastas que pretendem incluir. Após a seleção, os itens são obtidos para o Dataverse e indexados para utilização. As pastas adicionadas incluem todos os ficheiros e subpastas suportados dentro dessa pasta até ao limite total de ficheiros.
SharePoint
Os documentos do SharePoint permitem que os criadores utilizem uma interface de seleção de ficheiros para escolher os ficheiros e pastas que pretendem incluir. Após a seleção, os itens são obtidos para o Dataverse e indexados para utilização. As pastas adicionadas incluem todos os ficheiros e subpastas suportados dentro dessa pasta até ao limite total de ficheiros. Atualmente não existe suporte para Páginas.
Salesforce
O conector do Salesforce para dados não estruturados suporta a capacidade de obter Bases de Dados de Conhecimento que contêm artigos de conhecimento. Os criadores selecionam uma Base de Dados de Conhecimento e todos os artigos dessa Base de Dados de Conhecimento são indexados para utilização. Não é possível selecionar artigos ou tópicos individuais. Ao consultar os dados, não existe a possibilidade de especificar um artigo ou base de dados de conhecimento específico. A lista de Conhecimentos apresenta um único objeto para todos os objetos de conhecimento selecionados ao criar a origem.
ServiceNow
O conector do ServiceNow para dados não estruturados suporta a capacidade de obter Bases de Dados de Conhecimento que contêm artigos de conhecimento. As Bases de Dados de Conhecimento contêm artigos. Os criadores selecionam uma Base de Dados de Conhecimento e todos os artigos dessa Base de Dados de Conhecimento são indexados para utilização. Não é possível selecionar artigos individuais. Ao consultar os dados, não existe a possibilidade de especificar uma base de dados de conhecimento, pasta ou artigo individual. A lista de Conhecimentos apresenta um único objeto para todos os objetos de conhecimento selecionados ao criar a origem.
Confluência
O conector do Confluence para dados não estruturados suporta a obtenção de espaços que contêm páginas, sendo que as subpastas também são suportadas. Não é possível selecionar páginas individuais. Ao consultar os dados, não existe a possibilidade de especificar uma página. A lista de Conhecimentos apresenta um único objeto para todas as páginas dentro do espaço.
Zendesk
O conector do Zendesk para dados não estruturados suporta a capacidade de obter a base de dados de conhecimento que contém artigos de conhecimento. Não é possível selecionar artigos, categorias ou secções individuais. Ao consultar os dados, não é possível especificar um artigo, categoria ou secção. A lista de Conhecimentos apresenta um único objeto para todos os artigos dentro da base de dados de conhecimento.
Segurança
Quando um utilizador consulta um agente que está a utilizar uma origem do Conector do Power Platform, são realizadas algumas verificações de autorização.
Acesso ao Conector
Quando um fabricante utiliza pela primeira vez uma fonte baseada em conector, é-lhe pedido que selecione um conector do Power Platform ou que adicione um. Este processo garante que os dados são partilhados apenas com os criadores que possuem as permissões adequadas e fornece acesso à própria origem de dados.
Acesso ao conteúdo
Quando é feita uma consulta, as informações de ligação do utilizador são utilizadas para verificar a origem de dados e garantir que este tem permissão para ver o conteúdo. Embora os segmentos e índices sejam armazenados localmente no Dataverse, é realizada uma verificação em tempo real nas consultas para garantir que o utilizador atual tem acesso aos dados antes de fornecer um resumo ou uma resposta.
Nota
- Se um utilizador não tiver permissões para um conjunto específico de ficheiros ou artigos da base de dados de conhecimento, não será apresentado qualquer resultado e receberá a mensagem padrão "nenhum resultado encontrado". Se os utilizadores acreditarem que deveria haver resultados para aquela origem, precisam de contactar os seus administradores para garantir que têm permissões para aceder aos dados que estão a tentar consultar.
- As informações de permissão de conteúdo não são armazenadas localmente. Todas as verificações de permissão são feitas em direto com a fonte para garantir que sejam as mais atualizadas.
Frequência de sincronização e atualização de ficheiros
Os ficheiros ligados do OneDrive e SharePoint, bem como os artigos de conhecimento não estruturados, são mantidos atualizados através de uma tarefa de sincronização agendada. Esta tarefa é executada automaticamente em segundo plano, atualizando o conteúdo dos ficheiros e reindexando as alterações para fornecer resultados precisos para as consultas. As atualizações gerem não só as alterações de conteúdo, mas também garantem que qualquer conteúdo eliminado da origem já não aparece como parte das respostas de nenhuma consulta. Atualmente, não há forma de acionar uma atualização manualmente.
Para obter mais informações sobre o tempo de frequência de atualização, aceda a Limites da fonte de conhecimento de dados não estruturados do Copilot Studio.
Licenciamento
Todos os pedidos que envolvam conhecimento são cobrados de acordo com as taxas de mensagens de respostas generativas do Microsoft Copilot. Para mais informações, consulte Taxas e gestão de faturação.
Se as fontes de conhecimento exigirem a ingestão de dados, o armazenamento desses dados e os índices correspondentes para os recuperar estarão sujeitos às permissões de armazenamento que o cliente possui. Para mais informações sobre a pesquisa em linguagem natural do Dataverse, consulte Melhorar as experiências com tecnologia de IA utilizando a pesquisa do Dataverse.
Limites e limitações
Ao ativar o suporte de dados não estruturados pela primeira vez, pode haver um atraso de 5 a 30 minutos para a configuração e indexação do Dataverse antes de os ficheiros adicionados serem processados. A duração depende do tamanho do ambiente Dataverse atual.
Cada agente pode ter um máximo de 500 objetos de conhecimento. Estes objetos podem ser ficheiros, pastas, artigos de conhecimento, sites ou outras origens.
Atualmente, apenas cinco origens diferentes podem ser utilizadas simultaneamente num agente. Por exemplo, SharePoint, Dataverse, OneDrive ou outras origens.
Para mais informações sobre limites e limitações específicos para as origens de dados não estruturadas suportadas, consulte Limites da fonte de conhecimento de dados não estruturados do Copilot Studio.
Nota
Os agentes do Copilot Studio necessitam da pesquisa do Dataverse para utilizar esta fonte de conhecimento. Se não conseguir adicionar um ficheiro compatível com o Dataverse a um agente, peça ao seu administrador para ativar a pesquisa do Dataverse no seu ambiente. Para mais informações sobre a pesquisa Dataverse e como a gerir, consulte O que é a pesquisa do Dataverse e Configurar a pesquisa Dataverse para o seu ambiente.
FAQ
O ícone do SharePoint não está a ser apresentado na secção Carregar ficheiros do diálogo Adicionar conhecimento?
Existe um pequeno atraso entre a instalação de uma solução e a sua visualização em todas as organizações existentes. Para iniciar uma atualização manual, siga os seguintes passos:
- Inicie sessão no centro de administração do Power Platform utilizando credenciais de administrador.
- No painel de navegação lateral, selecione Gerir.
- A partir da lista de produtos, selecione Aplicações do Dynamics 365. Abre-se um painel.
- Procure por "PowerAIExtensions".
- Selecione os três pontos (...) para Microsoft Dynamics 365 - PowerAIExtensions e selecione Instalar.
- No menu pendente, selecione o seu ambiente e, em seguida, selecione Instalar.
- Depois de concluída a instalação, abra Power Apps numa nova janela.
- No painel de navegação à esquerda, selecione Soluções.
- Selecione Ver Histórico.
- Procure por "PowerAIExtensions_Anchor" e verifique se a versão é 1.01.688 ou superior.
No diálogo Adicionar conhecimento, qual é a diferença entre as duas opções do SharePoint?
No diálogo Adicionar conhecimento, existem duas opções do SharePoint. A opção SharePoint na secção de carregamento de ficheiros (1) é utilizada para carregar ficheiros ou pastas individuais do SharePoint e ativa as capacidades de sincronização de ficheiros. A outra opção SharePoint (2) oferece o suporte total do SharePoint no Copilot Studio.

O que acontece quando adiciono mais de 500 objetos de conhecimento ao meu agente?
É impedido de adicionar mais objetos a menos que primeiro elimine os anteriores.
Cada agente tem o seu próprio índice da fonte de conhecimento?
As fontes de conhecimento são armazenadas no Dataverse para utilização no ambiente em que foram criadas. Se a mesma pasta do SharePoint for utilizada em vários agentes, será utilizada uma única instância da pasta para todos os agentes.
O que acontece se selecionar uma pasta que tenha mais ficheiros, pastas e subpastas do que o número máximo permitido ao adicionar uma origem do SharePoint ou do OneDrive?
O Copilot Studio recupera e indexa até ao número máximo de ficheiros, pastas e subpastas, e indexa-os. Os restantes não são processados. Atualmente, não existe nenhuma mensagem a indicar o que foi ou não processado.
Um dos ficheiros que adicionei (ou que fazia parte de uma pasta que adicionei) é apresentado como parte da fonte de conhecimento, mas não consigo obter respostas a partir dele. Porquê?
Este problema pode estar relacionado com um dos seguintes motivos:
- O ficheiro ou a pasta está definido como "Pronto" na página Conhecimento.
- Certifique-se de que o nome do ficheiro não inclui um caráter não suportado (especificamente para ficheiros do SharePoint).
- Certifique-se de que o ficheiro não tem a definição de sensibilidade de Confidencial ou Altamente Confidencial, nem tem proteção por palavra-passe.
- Certifique-se de que é um tipo de ficheiro compatível.
- Se o ficheiro ou pasta for de um site do OneDrive ou SharePoint de outro utilizador, verifique se foi partilhado com o criador.
- Se o ficheiro for um ficheiro da base de dados de conhecimento, verifique se a sua conta tem permissões para ver o conteúdo no sistema de origem.