Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Observação
Para maior funcionalidade, o PyTorch também pode ser usado com DirectML no Windows.
Na etapa anterior deste tutorial, instalamos o PyTorch em sua máquina. Agora, vamos usá-lo para configurar nosso código com os dados que usaremos para criar nosso modelo.
Abra um novo projeto no Visual Studio.
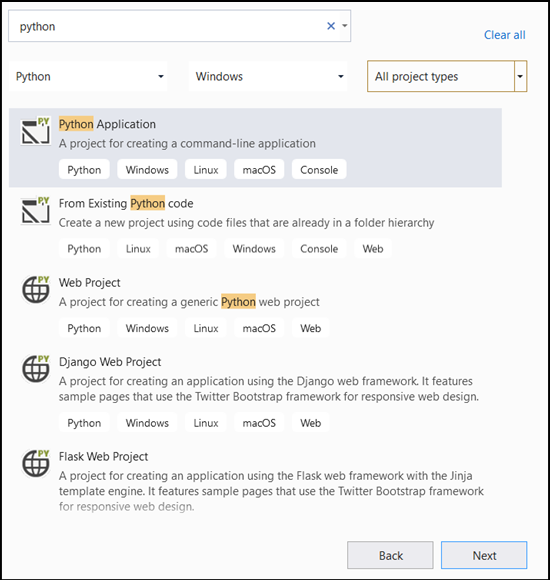
- Abra o Visual Studio e escolha
create a new project.

- Na barra de pesquisa, digite
Pythone selecionePython Applicationcomo seu modelo de projeto.
- Na janela de configuração:
- Atribua um nome ao seu projeto. Aqui, chamamos-lhe PyTorchTraining.
- Escolha a localização do seu projeto.
- Se você estiver usando o VS2019, verifique se
Create directory for solutionestá marcado. - Se estiver a utilizar o VS 2017, certifique-se de que
Place solution and project in the same directorynão está marcado.
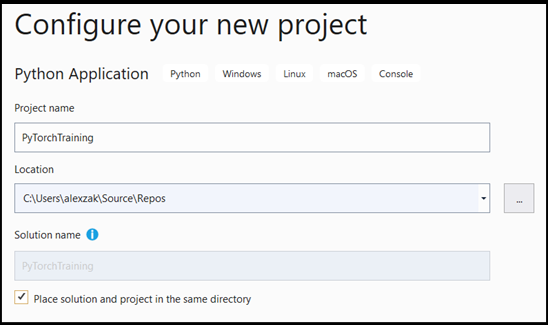
Pressione create para criar seu projeto.
Criar um interpretador Python
Agora, você precisa definir um novo interpretador Python. Isso deve incluir o pacote PyTorch que você instalou recentemente.
- Navegue até a seleção do intérprete e selecione
Add environment:

-
Add environmentNa janela, selecioneExisting environmente escolhaAnaconda3 (3.6, 64-bit). Isso inclui o pacote PyTorch.

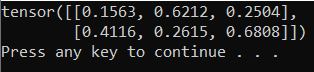
Para testar o novo interpretador Python e o pacote PyTorch, insira o seguinte código no PyTorchTraining.py arquivo:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
A saída deve ser um tensor 5x3 aleatório semelhante ao abaixo.
Observação
Interessado em saber mais? Visite o site oficial do PyTorch.
Carregar o conjunto de dados
Você usará a classe PyTorch torchvision para carregar os dados.
A biblioteca Torchvision inclui vários conjuntos de dados populares, como Imagenet, CIFAR10, MNIST, etc, arquiteturas de modelo e transformações de imagem comuns para visão computacional. Isso torna o carregamento de dados no PyTorch um processo bastante fácil.
CIFAR10
Aqui, usaremos o conjunto de dados CIFAR10 para criar e treinar o modelo de classificação de imagem. CIFAR10 é um conjunto de dados amplamente utilizado para pesquisa de aprendizado de máquina. É composto por 50.000 imagens de treinamento e 10.000 imagens de teste. Todos eles são de tamanho 3x32x32, o que significa imagens coloridas de 3 canais de 32x32 pixels de tamanho.
As imagens dividem-se em 10 classes: «avião» (0), «automóvel» (1), «pássaro» (2), «gato» (3) , «veado» (4), «cão» (5), «sapo» (6), «cavalo» (7), «navio» (8), «camião» (9).
Você seguirá três etapas para carregar e ler o conjunto de dados CIFAR10 no PyTorch:
- Definir transformações a serem aplicadas à imagem: Para treinar o modelo, você precisa transformar as imagens em Tensores de intervalo normalizado [-1,1].
- Crie uma instância do conjunto de dados disponível e carregue o conjunto de dados: para carregar os dados, você usará a
torch.utils.data.Datasetclasse - uma classe abstrata para representar um conjunto de dados. O conjunto de dados será baixado localmente somente na primeira vez que você executar o código. - Acesse os dados usando o DataLoader. Para obter o acesso aos dados e colocá-los na memória, você usará a
torch.utils.data.DataLoaderclasse. O DataLoader no PyTorch encapsula um conjunto de dados e fornece acesso aos dados subjacentes. Este invólucro conterá lotes de imagens por tamanho de lote definido.
Você repetirá essas três etapas para conjuntos de treinamento e teste.
- Abra o
PyTorchTraining.py fileno Visual Studio e adicione o código a seguir. Isso trata das três etapas acima para os conjuntos de dados de treinamento e teste do CIFAR10.
from torchvision.datasets import CIFAR10
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
# Loading and normalizing the data.
# Define transformations for the training and test sets
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR10 dataset consists of 50K training images. We define the batch size of 10 to load 5,000 batches of images.
batch_size = 10
number_of_labels = 10
# Create an instance for training.
# When we run this code for the first time, the CIFAR10 train dataset will be downloaded locally.
train_set =CIFAR10(root="./data",train=True,transform=transformations,download=True)
# Create a loader for the training set which will read the data within batch size and put into memory.
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
print("The number of images in a training set is: ", len(train_loader)*batch_size)
# Create an instance for testing, note that train is set to False.
# When we run this code for the first time, the CIFAR10 test dataset will be downloaded locally.
test_set = CIFAR10(root="./data", train=False, transform=transformations, download=True)
# Create a loader for the test set which will read the data within batch size and put into memory.
# Note that each shuffle is set to false for the test loader.
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)
print("The number of images in a test set is: ", len(test_loader)*batch_size)
print("The number of batches per epoch is: ", len(train_loader))
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Na primeira vez que executar este código, o conjunto de dados CIFAR10 será transferido para o seu dispositivo.

Próximas Etapas
Com os dados prontos, é hora de treinar nosso modelo PyTorch