Nota
O acesso a esta página requer autorização. Podes tentar iniciar sessão ou mudar de diretório.
O acesso a esta página requer autorização. Podes tentar mudar de diretório.
Observação
Para maior funcionalidade, o PyTorch também pode ser usado com DirectML no Windows.
Na etapa anterior deste tutorial, adquirimos o conjunto de dados que usaremos para treinar nosso classificador de imagens com o PyTorch. Agora, é hora de colocar esses dados em uso.
Para treinar o classificador de imagens com o PyTorch, você precisa concluir as seguintes etapas:
- Carregue os dados. Se você fez a etapa anterior deste tutorial, você já lidou com isso.
- Defina uma rede neural de convolução.
- Defina uma função de perda.
- Treine o modelo nos dados de treinamento.
- Teste a rede nos dados de teste.
Defina uma rede neural de convolução.
Para construir uma rede neural com o PyTorch, você usará o torch.nn pacote. Este pacote contém módulos, classes extensíveis e todos os componentes necessários para construir redes neurais.
Aqui, você criará uma rede neural de convolução básica (CNN) para classificar as imagens do conjunto de dados CIFAR10.
Uma CNN é uma classe de redes neurais, definidas como redes neurais multicamadas projetadas para detetar características complexas em dados. Eles são mais comumente usados em aplicações de visão computacional.
A nossa rede será estruturada com as seguintes 14 camadas:
Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> MaxPool -> Conv -> BatchNorm -> ReLU -> Conv -> BatchNorm -> ReLU -> Linear.
A camada de convolução
A camada de convolução é uma camada principal da CNN que nos ajuda a detetar características em imagens. Cada uma das camadas tem um número de canais para detetar recursos específicos em imagens e um número de kernels para definir o tamanho do recurso detetado. Portanto, uma camada de convolução com 64 canais e tamanho do kernel de 3 x 3 detetaria 64 características distintas, cada uma de tamanho 3 x 3. Ao definir uma camada de convolução, você fornece o número de canais de entrada, o número de canais de saída e o tamanho do kernel. O número de canais de saída na camada serve como o número de canais de entrada para a próxima camada.
Por exemplo: Uma camada de convolução com canais de entrada=3, canais de saída=10 e tamanho do filtro=6 receberá a imagem RGB (3 canais) como entrada e aplicará 10 detetores de características às imagens com o tamanho do filtro de 6x6. Tamanhos menores de kernel reduzirão o tempo computacional e o compartilhamento de peso.
Outras camadas
As seguintes outras camadas estão envolvidas na nossa rede:
- A
ReLUcamada é uma função de ativação para definir todas as características recebidas como iguais ou superiores a 0. Quando você aplica essa camada, qualquer número menor que 0 é alterado para zero, enquanto outros são mantidos iguais. - A
BatchNorm2dcamada aplica normalização nas entradas para ter média zero e variância unitária e aumentar a precisão da rede. - A
MaxPoolcamada nos ajudará a garantir que a localização de um objeto em uma imagem não afetará a capacidade da rede neural de detetar suas características específicas. - A
Linearcamada é a camada final em nossa rede, que calcula as pontuações de cada uma das classes. No conjunto de dados CIFAR10, há dez classes de rótulos. O rótulo com a pontuação mais alta será aquele que o modelo prevê. Na camada linear, você tem que especificar o número de recursos de entrada e o número de recursos de saída que devem corresponder ao número de classes.
Como funciona uma Rede Neural?
A CNN é uma rede feed-forward. Durante o processo de treinamento, a rede processará a entrada através de todas as camadas, calculará a perda para entender até onde o rótulo previsto da imagem está caindo do correto e propagará os gradientes de volta para a rede para atualizar os pesos das camadas. Ao iterar sobre um enorme conjunto de dados de entradas, a rede "aprenderá" a definir os seus pesos para alcançar os melhores resultados.
Uma função forward calcula o valor da função de perda e a função backward calcula os gradientes dos parâmetros aprendíveis. Quando você cria nossa rede neural com PyTorch, você só precisa definir a função forward. A função backward será definida automaticamente.
- Copie o código a seguir para o
PyTorchTraining.pyarquivo no Visual Studio para definir a CCN.
import torch
import torch.nn as nn
import torchvision
import torch.nn.functional as F
# Define a convolution neural network
class Network(nn.Module):
def __init__(self):
super(Network, self).__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=1)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*10*10, 10)
def forward(self, input):
output = F.relu(self.bn1(self.conv1(input)))
output = F.relu(self.bn2(self.conv2(output)))
output = self.pool(output)
output = F.relu(self.bn4(self.conv4(output)))
output = F.relu(self.bn5(self.conv5(output)))
output = output.view(-1, 24*10*10)
output = self.fc1(output)
return output
# Instantiate a neural network model
model = Network()
Observação
Interessado em aprender mais sobre a rede neural com o PyTorch? Confira a documentação do PyTorch
Definir uma função de perda
Uma função de perda calcula um valor que estima a distância entre a saída e o destino. O principal objetivo é reduzir o valor da função de perda alterando os valores do vetor de peso através da retropropagação em redes neurais.
O valor de perda é diferente da precisão do modelo. A função de perda nos dá a compreensão de como um modelo se comporta bem após cada iteração de otimização no conjunto de treinamento. A precisão do modelo é calculada sobre os dados do teste e mostra a porcentagem da previsão correta.
No PyTorch, o pacote de rede neural contém várias funções de perda que formam os blocos de construção de redes neurais profundas. Neste tutorial, você usará uma função de perda de classificação baseada em Definir a função de perda com perda de entropia cruzada de classificação e um otimizador de Adam. A taxa de aprendizagem (lr) define o controle de quanto você está ajustando os pesos da nossa rede em relação ao gradiente de perda. Você irá defini-lo como 0,001. Quanto mais baixo, mais lento será o treino.
- Copie o código a seguir para o
PyTorchTraining.pyarquivo no Visual Studio para definir a função de perda e um otimizador.
from torch.optim import Adam
# Define the loss function with Classification Cross-Entropy loss and an optimizer with Adam optimizer
loss_fn = nn.CrossEntropyLoss()
optimizer = Adam(model.parameters(), lr=0.001, weight_decay=0.0001)
Treine o modelo nos dados de treinamento.
Para treinares o modelo, tens que percorrer o nosso iterador de dados, alimentar as entradas na rede e otimizar. O PyTorch não tem uma biblioteca dedicada para uso de GPU, mas você pode definir manualmente o dispositivo de execução. O dispositivo será uma GPU Nvidia, se existir na sua máquina, ou a sua CPU, se não existir.
- Adicione o seguinte código ao
PyTorchTraining.pyficheiro
from torch.autograd import Variable
# Function to save the model
def saveModel():
path = "./myFirstModel.pth"
torch.save(model.state_dict(), path)
# Function to test the model with the test dataset and print the accuracy for the test images
def testAccuracy():
model.eval()
accuracy = 0.0
total = 0.0
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
with torch.no_grad():
for data in test_loader:
images, labels = data
# run the model on the test set to predict labels
outputs = model(images.to(device))
# the label with the highest energy will be our prediction
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
accuracy += (predicted == labels.to(device)).sum().item()
# compute the accuracy over all test images
accuracy = (100 * accuracy / total)
return(accuracy)
# Training function. We simply have to loop over our data iterator and feed the inputs to the network and optimize.
def train(num_epochs):
best_accuracy = 0.0
# Define your execution device
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("The model will be running on", device, "device")
# Convert model parameters and buffers to CPU or Cuda
model.to(device)
for epoch in range(num_epochs): # loop over the dataset multiple times
running_loss = 0.0
running_acc = 0.0
for i, (images, labels) in enumerate(train_loader, 0):
# get the inputs
images = Variable(images.to(device))
labels = Variable(labels.to(device))
# zero the parameter gradients
optimizer.zero_grad()
# predict classes using images from the training set
outputs = model(images)
# compute the loss based on model output and real labels
loss = loss_fn(outputs, labels)
# backpropagate the loss
loss.backward()
# adjust parameters based on the calculated gradients
optimizer.step()
# Let's print statistics for every 1,000 images
running_loss += loss.item() # extract the loss value
if i % 1000 == 999:
# print every 1000 (twice per epoch)
print('[%d, %5d] loss: %.3f' %
(epoch + 1, i + 1, running_loss / 1000))
# zero the loss
running_loss = 0.0
# Compute and print the average accuracy fo this epoch when tested over all 10000 test images
accuracy = testAccuracy()
print('For epoch', epoch+1,'the test accuracy over the whole test set is %d %%' % (accuracy))
# we want to save the model if the accuracy is the best
if accuracy > best_accuracy:
saveModel()
best_accuracy = accuracy
Teste os dados de teste no modelo.
Agora, você pode testar o modelo com um lote de imagens do nosso conjunto de testes.
- Adicione o seguinte código ao ficheiro
PyTorchTraining.py.
import matplotlib.pyplot as plt
import numpy as np
# Function to show the images
def imageshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# Function to test the model with a batch of images and show the labels predictions
def testBatch():
# get batch of images from the test DataLoader
images, labels = next(iter(test_loader))
# show all images as one image grid
imageshow(torchvision.utils.make_grid(images))
# Show the real labels on the screen
print('Real labels: ', ' '.join('%5s' % classes[labels[j]]
for j in range(batch_size)))
# Let's see what if the model identifiers the labels of those example
outputs = model(images)
# We got the probability for every 10 labels. The highest (max) probability should be correct label
_, predicted = torch.max(outputs, 1)
# Let's show the predicted labels on the screen to compare with the real ones
print('Predicted: ', ' '.join('%5s' % classes[predicted[j]]
for j in range(batch_size)))
Finalmente, vamos adicionar o código principal. Isso iniciará o treinamento do modelo, salvará o modelo e exibirá os resultados na tela. Executaremos apenas duas iterações [train(2)] ao longo do conjunto de treinamento, para que o processo de treinamento não demore muito.
- Adicione o seguinte código ao ficheiro
PyTorchTraining.py.
if __name__ == "__main__":
# Let's build our model
train(5)
print('Finished Training')
# Test which classes performed well
testAccuracy()
# Let's load the model we just created and test the accuracy per label
model = Network()
path = "myFirstModel.pth"
model.load_state_dict(torch.load(path))
# Test with batch of images
testBatch()
Vamos fazer o teste! Verifique se os menus suspensos na barra de ferramentas superior estão configurados como Depurar. Altere a plataforma de solução para x64 para executar o projeto em sua máquina local se o dispositivo for de 64 bits ou x86 se for de 32 bits.
Escolher o número de época (o número de passagens completas pelo conjunto de dados de treinamento) igual a dois ([train(2)]) resultará na iteração duas vezes através de todo o conjunto de dados de teste de 10.000 imagens. Levará cerca de 20 minutos para completar o treinamento sobre CPU Intel de 8ª geração, e o modelo deve atingir mais ou menos 65% de taxa de sucesso na classificação de dez rótulos.
- Para executar o projeto, clique no botão Iniciar depuração na barra de ferramentas ou pressione F5.
A janela do console aparecerá e poderá ver o processo de treinamento.
Como definiu, o valor de perda será exibido a cada 1.000 blocos de imagens ou cinco vezes para cada iteração do conjunto de treinamento. Você espera que o valor de perda diminua a cada loop.
Você também verá a precisão do modelo após cada iteração. A precisão do modelo é diferente do valor de perda. A função de perda nos dá a compreensão de como um modelo se comporta bem após cada iteração de otimização no conjunto de treinamento. A precisão do modelo é calculada sobre os dados do teste e mostra a porcentagem da previsão correta. No nosso caso, ele nos dirá quantas imagens do conjunto de teste de 10.000 imagens nosso modelo foi capaz de classificar corretamente após cada iteração de treinamento.
Quando o treinamento estiver concluído, você deve esperar ver o resultado semelhante ao abaixo. Os seus números não serão exatamente os mesmos - o treino depende de muitos fatores e nem sempre retornará resultados idênticos - mas devem ser semelhantes.
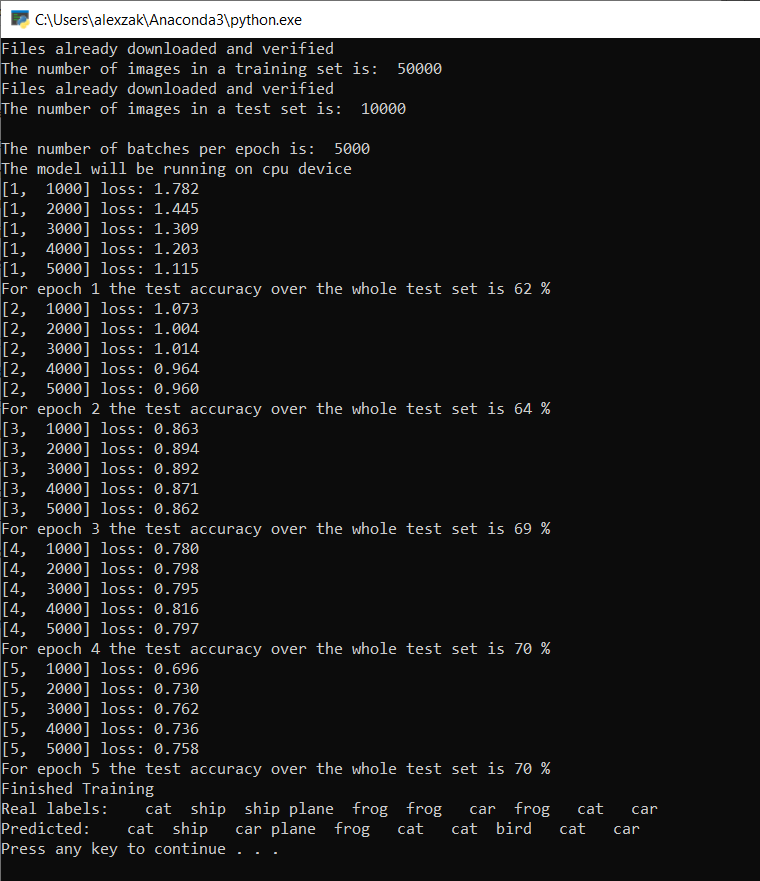
Depois de correr apenas 5 épocas, a taxa de sucesso do modelo é de 70%. Este é um bom resultado para um modelo básico treinado por um curto período de tempo!
Ao testar com o lote de imagens, o modelo acertou 7 imagens de um lote de 10. Nada ruim e consistente com a taxa de sucesso do modelo.

Você pode verificar quais classes nosso modelo pode prever melhor. Simplesmente adicione para executar o código abaixo:
-
Opcional - adicione a seguinte
testClassessfunção noPyTorchTraining.pyarquivo, adicione uma chamada desta função -testClassess()dentro da função principal -__name__ == "__main__".
# Function to test what classes performed well
def testClassess():
class_correct = list(0. for i in range(number_of_labels))
class_total = list(0. for i in range(number_of_labels))
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs, 1)
c = (predicted == labels).squeeze()
for i in range(batch_size):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
for i in range(number_of_labels):
print('Accuracy of %5s : %2d %%' % (
classes[i], 100 * class_correct[i] / class_total[i]))
O resultado é o seguinte:

Próximas Etapas
Agora que temos um modelo de classificação, o próximo passo é converter o modelo para o formato ONNX