หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
บทความนี้สรุปวิธีการใช้กิจกรรมการคัดลอกในไปป์ไลน์เพื่อคัดลอกข้อมูลจากและไปยังฐานข้อมูล Azure SQL
การกําหนดค่าที่รองรับ
สําหรับการกําหนดค่าของแต่ละแท็บภายใต้กิจกรรมการคัดลอก ให้ไปที่ส่วนต่อไปนี้ตามลําดับ
General
โปรดดูคําแนะนําการตั้งค่าทั่วไปเพื่อกําหนดค่าแท็บ การตั้งค่าทั่วไป
ที่มา
คุณสมบัติต่อไปนี้ได้รับการสนับสนุนสําหรับฐานข้อมูล Azure SQL ภายใต้แท็บ แหล่งที่มา ของกิจกรรมการคัดลอก
คุณสมบัติต่อไปนี้ เป็นสิ่งจําเป็น:
- การเชื่อมต่อ: เลือกการเชื่อมต่อฐานข้อมูล Azure SQL จากรายการการเชื่อมต่อ ถ้าไม่มีการเชื่อมต่อ ให้สร้างการเชื่อมต่อฐานข้อมูล Azure SQL ใหม่โดยเลือก ใหม่
- ชนิดการเชื่อมต่อ: เลือก ฐานข้อมูล Azure SQL
- ตาราง: เลือกตารางในฐานข้อมูลของคุณจากรายการดรอปดาวน์ หรือตรวจสอบ แก้ไข เพื่อป้อนชื่อตารางของคุณด้วยตนเอง
- แสดงตัวอย่างข้อมูล: เลือก แสดงตัวอย่างข้อมูล เพื่อดูตัวอย่างข้อมูลในตารางของคุณ
ภายใต้ ขั้นสูง คุณสามารถระบุฟิลด์ต่อไปนี้:
ใช้แบบสอบถาม: คุณสามารถเลือก ตารางแบบสอบถาม หรือ กระบวนงานที่เก็บไว้ รายการต่อไปนี้อธิบายการกําหนดค่าของการตั้งค่าแต่ละรายการ:
ตาราง: อ่านข้อมูลจากตารางที่คุณระบุไว้ใน ตาราง หากคุณเลือกปุ่มนี้
คิวรี: ระบุคิวรี SQL แบบกําหนดเองเพื่ออ่านข้อมูล ตัวอย่างคือ
select * from MyTable. หรือเลือกไอคอนดินสอเพื่อแก้ไขในตัวแก้ไขโค้ด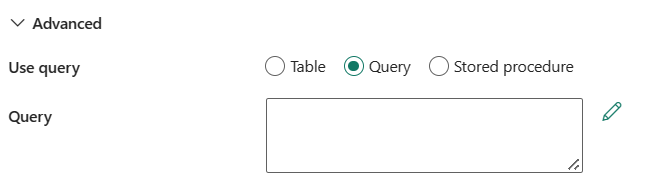
กระบวนงานที่เก็บไว้: ใช้กระบวนงานที่เก็บไว้ที่อ่านข้อมูลจากตารางต้นฉบับ คําสั่ง SQL สุดท้ายต้องเป็นคําสั่ง SELECT ในกระบวนงานที่เก็บไว้
ชื่อกระบวนงานที่เก็บไว้: เลือกกระบวนงานที่เก็บไว้หรือระบุชื่อกระบวนงานที่เก็บไว้ด้วยตนเองเมื่อทําเครื่องหมายที่ไฟล์ แก้ไข กล่อง เพื่ออ่านข้อมูลจากตารางต้นฉบับ
พารามิเตอร์กระบวนงานที่เก็บไว้: ระบุค่าสําหรับพารามิเตอร์กระบวนงานที่เก็บไว้ ค่าที่อนุญาตคือคู่ชื่อหรือค่า ชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์ต้องตรงกับชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์กระบวนงานที่เก็บไว้

การหมดเวลาของคิวรี (นาที): ระบุการหมดเวลาสําหรับการดําเนินการคําสั่งคิวรี ค่าเริ่มต้นคือ 120 นาที ถ้าตั้งค่าพารามิเตอร์สําหรับคุณสมบัตินี้ ค่าที่อนุญาตคือช่วงเวลา เช่น "02:00:00" (120 นาที)
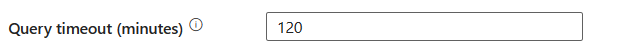
ระดับการแยก: ระบุลักษณะการล็อกธุรกรรมสําหรับแหล่งข้อมูล SQL ค่าที่อนุญาตคือ: None, ReadCommitted, ReadUncommitted, RepeatableRead, Serializable หรือ Snapshot หากไม่ได้ระบุ จะใช้ ไม่มี ระดับการแยก อ้างถึง IsolationLevel Enum สําหรับรายละเอียดเพิ่มเติม

ตัวเลือกพาร์ติชัน: ระบุตัวเลือกการแบ่งพาร์ติชันข้อมูลที่ใช้ในการโหลดข้อมูลจากฐานข้อมูล Azure SQL ค่าที่อนุญาตคือ: ไม่มี (ค่าเริ่มต้น) พาร์ติชันทางกายภาพของตาราง และช่วงไดนามิก เมื่อเปิดใช้งานตัวเลือกพาร์ติชัน (นั่นคือ ไม่ใช่ ไม่มี) ระดับของความขนานในการโหลดข้อมูลพร้อมกันจากฐานข้อมูล Azure SQL จะถูกควบคุมโดยการตั้งค่า การคัดลอกแบบขนาน ในกิจกรรมการคัดลอก

ไม่มี: เลือกการตั้งค่านี้เพื่อไม่ใช้พาร์ติชัน
พาร์ติชันทางกายภาพของตาราง: เมื่อคุณใช้พาร์ติชันทางกายภาพ คอลัมน์พาร์ติชันและกลไกจะถูกกําหนดโดยอัตโนมัติตามข้อกําหนดของตารางทางกายภาพของคุณ
ช่วงไดนามิก: เมื่อคุณใช้คิวรีที่เปิดใช้งานแบบขนาน จําเป็นต้องใช้พารามิเตอร์พาร์ติชันช่วง(
?DfDynamicRangePartitionCondition) ตัวอย่างแบบสอบถาม:SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition.-
ชื่อคอลัมน์พาร์ติชัน: ระบุชื่อของคอลัมน์ต้นฉบับเป็นจํานวนเต็มหรือชนิดวันที่/วันที่และเวลา (
int,smallint, ,bigint,date,smalldatetimedatetimedatetime2หรือdatetimeoffset) ที่ใช้โดยการแบ่งพาร์ติชันช่วงสําหรับการคัดลอกแบบขนาน หากไม่ได้ระบุ ดัชนีหรือคีย์หลักของตารางจะถูกตรวจหาโดยอัตโนมัติและใช้เป็นคอลัมน์พาร์ติชัน - ขอบเขตบนของพาร์ติชัน: ระบุค่าสูงสุดของคอลัมน์พาร์ติชันสําหรับการแยกช่วงพาร์ติชัน ค่านี้ใช้เพื่อกําหนดการก้าวของพาร์ติชัน ไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางหรือผลลัพธ์แบบสอบถามจะถูกแบ่งพาร์ติชันและคัดลอก
- ขอบเขตล่างของพาร์ติชัน: ระบุค่าต่ําสุดของคอลัมน์พาร์ติชันสําหรับการแยกช่วงพาร์ติชัน ค่านี้ใช้เพื่อกําหนดการก้าวของพาร์ติชัน ไม่ใช่สําหรับการกรองแถวในตาราง แถวทั้งหมดในตารางหรือผลลัพธ์แบบสอบถามจะถูกแบ่งพาร์ติชันและคัดลอก
-
ชื่อคอลัมน์พาร์ติชัน: ระบุชื่อของคอลัมน์ต้นฉบับเป็นจํานวนเต็มหรือชนิดวันที่/วันที่และเวลา (
คอลัมน์เพิ่มเติม: เพิ่มคอลัมน์ข้อมูลเพิ่มเติมเพื่อจัดเก็บเส้นทางสัมพัทธ์หรือค่าคงที่ของไฟล์ต้นฉบับ นิพจน์ได้รับการสนับสนุนสําหรับรุ่นหลัง สําหรับข้อมูลเพิ่มเติม ไปที่ เพิ่มคอลัมน์เพิ่มเติมระหว่างการคัดลอก


จุดหมาย
คุณสมบัติต่อไปนี้ได้รับการสนับสนุนสําหรับฐานข้อมูล Azure SQL ภายใต้แท็บ ปลายทาง ของกิจกรรมการคัดลอก

คุณสมบัติต่อไปนี้ เป็นสิ่งจําเป็น:
- การเชื่อมต่อ: เลือกการเชื่อมต่อฐานข้อมูล Azure SQL จากรายการการเชื่อมต่อ ถ้าไม่มีการเชื่อมต่อ ให้สร้างการเชื่อมต่อฐานข้อมูล Azure SQL ใหม่โดยเลือก ใหม่
- ชนิดการเชื่อมต่อ: เลือก ฐานข้อมูล Azure SQL
- ตาราง: เลือกตารางในฐานข้อมูลของคุณจากรายการดรอปดาวน์ หรือตรวจสอบ แก้ไข เพื่อป้อนชื่อตารางของคุณด้วยตนเอง
- แสดงตัวอย่างข้อมูล: เลือก แสดงตัวอย่างข้อมูล เพื่อดูตัวอย่างข้อมูลในตารางของคุณ
ภายใต้ ขั้นสูง คุณสามารถระบุฟิลด์ต่อไปนี้:
พฤติกรรมการเขียน: กําหนดลักษณะการเขียนเมื่อแหล่งที่มาเป็นไฟล์จากที่เก็บข้อมูลแบบไฟล์ คุณสามารถเลือก แทรกอัพเซิร์ต หรือ กระบวนงานที่เก็บไว้

แทรก: เลือกตัวเลือกนี้หากข้อมูลต้นฉบับของคุณมีการแทรก
อัปเซิร์ต: เลือกตัวเลือกนี้หากข้อมูลต้นฉบับของคุณมีทั้งการแทรกและการอัปเดต
ใช้ TempDB: ระบุว่าจะใช้ตารางชั่วคราวส่วนกลางหรือตารางทางกายภาพเป็นตารางชั่วคราวสําหรับ upsert โดยค่าเริ่มต้น บริการจะใช้ตารางชั่วคราวส่วนกลางเป็นตารางชั่วคราว และกล่องกาเครื่องหมายนี้จะถูกเลือก

เลือกสคีมา DB ของผู้ใช้: เมื่อไม่ได้เลือกกล่องกาเครื่องหมาย ใช้ TempDB ให้ระบุสคีมาชั่วคราวสําหรับการสร้างตารางชั่วคราวหากใช้ตารางทางกายภาพ
Note
คุณต้องมีสิทธิ์ในการสร้างและลบตาราง โดยค่าเริ่มต้น ตารางชั่วคราวจะใช้ Schema เดียวกันกับตารางปลายทาง

คอลัมน์หลัก: ระบุชื่อคอลัมน์สําหรับการระบุแถวที่ไม่ซ้ํากัน สามารถใช้ปุ่มเดียวหรือชุดปุ่มก็ได้ หากไม่ได้ระบุ จะใช้คีย์หลัก
กระบวนงานที่เก็บไว้: ใช้กระบวนงานที่เก็บไว้ซึ่งกําหนดวิธีการนําข้อมูลต้นฉบับไปใช้กับตารางเป้าหมาย กระบวนงานที่เก็บไว้นี้ถูกเรียกใช้ต่อชุดงาน
ชื่อกระบวนงานที่เก็บไว้: เลือกกระบวนงานที่เก็บไว้หรือระบุชื่อกระบวนงานที่เก็บไว้ด้วยตนเองเมื่อทําเครื่องหมายที่ไฟล์ แก้ไข กล่อง เพื่ออ่านข้อมูลจากตารางต้นฉบับ
พารามิเตอร์กระบวนงานที่เก็บไว้: ระบุค่าสําหรับพารามิเตอร์กระบวนงานที่เก็บไว้ ค่าที่อนุญาตคือคู่ชื่อหรือค่า ชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์ต้องตรงกับชื่อและตัวพิมพ์ใหญ่ของพารามิเตอร์กระบวนงานที่เก็บไว้
การล็อกตารางแทรกจํานวนมาก: เลือก ใช่ หรือ ไม่ใช่ ใช้การตั้งค่านี้เพื่อปรับปรุงประสิทธิภาพการคัดลอกในระหว่างการดําเนินการแทรกจํานวนมากบนตารางที่ไม่มีดัชนีจากไคลเอ็นต์หลายตัว สําหรับข้อมูลเพิ่มเติม ไปที่ BULK INSERT (Transact-SQL)
ตัวเลือกตาราง: ระบุว่าจะ สร้างตารางปลายทางโดยอัตโนมัติ หรือไม่หากไม่มีตารางตามสคีมาต้นทาง เลือก ไม่มี หรือ สร้างตารางอัตโนมัติ การสร้างตารางอัตโนมัติไม่ได้รับการสนับสนุนเมื่อปลายทางระบุกระบวนงานที่เก็บไว้
สคริปต์คัดลอกล่วงหน้า: ระบุสคริปต์สําหรับกิจกรรมการคัดลอกที่จะดําเนินการก่อนที่จะเขียนข้อมูลลงในตารางปลายทางในการเรียกใช้แต่ละครั้ง คุณสามารถใช้คุณสมบัตินี้เพื่อล้างข้อมูลที่โหลดไว้ล่วงหน้า
การหมดเวลาของชุดการเขียน: ระบุเวลารอให้การดําเนินการแทรกชุดงานเสร็จสิ้นก่อนที่จะหมดเวลา ค่าที่อนุญาตคือช่วงเวลา ค่าเริ่มต้นคือ "00:30:00" (30 นาที)
เขียนขนาดแบทช์: ระบุจํานวนแถวที่จะแทรกลงในตาราง SQL ต่อแบทช์ ค่าที่อนุญาตคือจํานวนเต็ม (จํานวนแถว) โดยค่าเริ่มต้น บริการจะกําหนดขนาดชุดงานที่เหมาะสมแบบไดนามิกตามขนาดแถว
การเชื่อมต่อพร้อมกันสูงสุด: ระบุขีดจํากัดบนของการเชื่อมต่อพร้อมกันที่สร้างขึ้นไปยังที่เก็บข้อมูลระหว่างการเรียกใช้กิจกรรม ระบุค่าเมื่อคุณต้องการจํากัดการเชื่อมต่อที่เกิดขึ้นพร้อมกันเท่านั้น
ปิดใช้งานการวิเคราะห์เมตริกประสิทธิภาพ: การตั้งค่านี้ใช้เพื่อรวบรวมเมตริก เช่น DTU, DWU, RU และอื่นๆ เพื่อคัดลอกการเพิ่มประสิทธิภาพและคําแนะนํา หากคุณกังวลเกี่ยวกับลักษณะการทํางานนี้ ให้เลือกกล่องกาเครื่องหมายนี้
การแม็ป
สําหรับการกําหนดค่าแท็บ การแม็ป ถ้าคุณไม่ได้ใช้ฐานข้อมูล Azure SQL ที่มีตารางสร้างอัตโนมัติเป็นปลายทางของคุณ ให้ไปที่ การแม็ป
ถ้าคุณใช้ฐานข้อมูล Azure SQL ที่มีตารางสร้างอัตโนมัติเป็นปลายทางของคุณ ยกเว้นการกําหนดค่าในการ แมป คุณสามารถแก้ไขชนิดสําหรับคอลัมน์ปลายทางของคุณได้ หลังจากเลือก นําเข้า Schema คุณสามารถระบุชนิดคอลัมน์ในปลายทางของคุณได้
ตัวอย่างเช่น ชนิดของคอลัมน์ ID ในแหล่งที่มาคือ int และคุณสามารถเปลี่ยนเป็นชนิดลอยได้เมื่อแม็ปกับคอลัมน์ปลายทาง

การตั้งค่า
สําหรับการกําหนดค่าแท็บการตั้งค่า ให้ไปที่ กําหนดการตั้งค่าอื่นๆ ภายใต้แท็บการตั้งค่า
คัดลอกแบบขนานจากฐานข้อมูล Azure SQL
ตัวเชื่อมต่อฐานข้อมูล Azure SQL ในกิจกรรมการคัดลอกให้การแบ่งพาร์ติชันข้อมูลในตัวเพื่อคัดลอกข้อมูลแบบขนาน คุณสามารถค้นหาตัวเลือกการแบ่งพาร์ติชันข้อมูลได้ที่แท็บ แหล่งที่มา ของกิจกรรมการคัดลอก
เมื่อคุณเปิดใช้งานการคัดลอกแบบแบ่งพาร์ติชัน กิจกรรมการคัดลอกจะเรียกใช้คิวรีแบบขนานกับแหล่งข้อมูลฐานข้อมูล Azure SQL ของคุณเพื่อโหลดข้อมูลตามพาร์ติชัน องศาขนานถูกควบคุมโดย ระดับการคัดลอกแบบขนาน ในแท็บการตั้งค่ากิจกรรมการคัดลอก ตัวอย่างเช่น ถ้าคุณตั้งค่า ระดับการคัดลอกแบบขนาน เป็น 4 บริการจะสร้างและเรียกใช้คิวรีสี่รายการพร้อมกันตามตัวเลือกและการตั้งค่าพาร์ติชันที่คุณระบุ และแต่ละคิวรีจะดึงข้อมูลบางส่วนจากฐานข้อมูล Azure SQL ของคุณ
ขอแนะนําให้คุณเปิดใช้งานการคัดลอกแบบขนานกับการแบ่งพาร์ติชันข้อมูล โดยเฉพาะอย่างยิ่งเมื่อคุณโหลดข้อมูลจํานวนมากจากฐานข้อมูล Azure SQL ของคุณ ต่อไปนี้เป็นการตั้งค่าคอนฟิกที่แนะนําสําหรับสถานการณ์ต่างๆ เมื่อคัดลอกข้อมูลไปยังที่เก็บข้อมูลตามไฟล์ ขอแนะนําให้เขียนลงในโฟลเดอร์เป็นหลายไฟล์ (ระบุเฉพาะชื่อโฟลเดอร์) ซึ่งในกรณีนี้ประสิทธิภาพจะดีกว่าการเขียนไปยังไฟล์เดียว
| สถานการณ์สมมติ | การตั้งค่าที่แนะนํา |
|---|---|
| โหลดเต็มที่จากโต๊ะขนาดใหญ่พร้อมพาร์ติชันทางกายภาพ |
ตัวเลือกพาร์ติชัน: พาร์ติชันทางกายภาพของตาราง ในระหว่างการดําเนินการ บริการจะตรวจพบพาร์ติชันทางกายภาพโดยอัตโนมัติ และคัดลอกข้อมูลตามพาร์ติชัน หากต้องการตรวจสอบว่าตารางของคุณมีพาร์ติชันจริงหรือไม่ คุณสามารถอ้างถึงแบบสอบถามนี้ |
| โหลดเต็มจากตารางขนาดใหญ่โดยไม่มีพาร์ติชันทางกายภาพในขณะที่มีคอลัมน์จํานวนเต็มหรือวันที่และเวลาสําหรับการแบ่งพาร์ติชันข้อมูล |
ตัวเลือกพาร์ติชัน: พาร์ติชันช่วงไดนามิก คอลัมน์พาร์ติชัน (ไม่บังคับ): ระบุคอลัมน์ที่ใช้ในการแบ่งพาร์ติชันข้อมูล หากไม่ได้ระบุ จะใช้คอลัมน์ดัชนีหรือคีย์หลัก ขอบเขตบนของพาร์ติชัน และ ขอบเขตล่างของพาร์ติชัน (ไม่บังคับ): ระบุว่าคุณต้องการกําหนดก้าวของพาร์ติชันหรือไม่ นี่ไม่ได้มีไว้สําหรับการกรองแถวในตารางแถวทั้งหมดในตารางจะถูกแบ่งพาร์ติชันและคัดลอก หากไม่ได้ระบุ ให้คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ ตัวอย่างเช่น ถ้าคอลัมน์พาร์ติชัน "ID" ของคุณมีค่าตั้งแต่ 1 ถึง 100 และคุณตั้งค่าขอบเขตล่างเป็น 20 และขอบเขตบนเป็น 80 โดยมีการคัดลอกแบบขนานเป็น 4 บริการจะดึงข้อมูลโดย 4 พาร์ติชัน - ID ในช่วง <=20, [21, 50], [51, 80] และ >=81 ตามลําดับ |
| โหลดข้อมูลจํานวนมากโดยใช้คิวรีแบบกําหนดเอง โดยไม่มีพาร์ติชันทางกายภาพ ในขณะที่มีคอลัมน์จํานวนเต็มหรือวันที่ / วันที่และเวลาสําหรับการแบ่งพาร์ติชันข้อมูล |
ตัวเลือกพาร์ติชัน: พาร์ติชันช่วงไดนามิก แบบสอบถาม: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.คอลัมน์พาร์ติชัน: ระบุคอลัมน์ที่ใช้ในการแบ่งพาร์ติชันข้อมูล ขอบเขตบนของพาร์ติชัน และ ขอบเขตล่างของพาร์ติชัน (ไม่บังคับ): ระบุว่าคุณต้องการกําหนดก้าวของพาร์ติชันหรือไม่ นี่ไม่ได้มีไว้สําหรับการกรองแถวในตารางแถวทั้งหมดในผลลัพธ์แบบสอบถามจะถูกแบ่งพาร์ติชันและคัดลอก หากไม่ได้ระบุ ให้คัดลอกกิจกรรมจะตรวจหาค่าโดยอัตโนมัติ ตัวอย่างเช่น ถ้าคอลัมน์พาร์ติชัน "ID" ของคุณมีค่าตั้งแต่ 1 ถึง 100 และคุณตั้งค่าขอบเขตล่างเป็น 20 และขอบเขตบนเป็น 80 โดยมีการคัดลอกแบบขนานเป็น 4 บริการจะดึงข้อมูลโดย 4 พาร์ติชัน - ID ในช่วง <=20, [21, 50], [51, 80] และ >=81 ตามลําดับ ต่อไปนี้เป็นตัวอย่างการสืบค้นเพิ่มเติมสําหรับสถานการณ์ต่างๆ •สอบถามทั้งตาราง: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition•แบบสอบถามจากตารางที่มีการเลือกคอลัมน์และตัวกรอง where-clause เพิ่มเติม: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>•แบบสอบถามด้วยแบบสอบถามย่อย: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>•แบบสอบถามด้วยพาร์ติชันในแบบสอบถามย่อย: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
แนวทางปฏิบัติที่ดีที่สุดในการโหลดข้อมูลด้วยตัวเลือกพาร์ติชัน:
- เลือกคอลัมน์ที่ไม่ซ้ํากันเป็นคอลัมน์พาร์ติชัน (เช่น คีย์หลักหรือคีย์เฉพาะ) เพื่อหลีกเลี่ยงการเบ้ของข้อมูล
- หากตารางมีพาร์ติชันในตัว ให้ใช้ตัวเลือกพาร์ติชัน พาร์ติชันทางกายภาพของตาราง เพื่อให้ได้ประสิทธิภาพที่ดีขึ้น
คิวรีตัวอย่างเพื่อตรวจสอบพาร์ติชันทางกายภาพ
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, pf.name AS PartitionFunctionName, c.name AS ColumnName, iif(pf.name is null, 'no', 'yes') AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.partition_schemes ps ON i.data_space_id = ps.data_space_id
LEFT JOIN sys.partition_functions pf ON pf.function_id = ps.function_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
หากตารางมีพาร์ติชันจริงคุณจะเห็น "HasPartition" เป็น "ใช่" ดังต่อไปนี้

ข้อมูลสรุปของตาราง
ตารางต่อไปนี้ประกอบด้วยข้อมูลเพิ่มเติมเกี่ยวกับกิจกรรมการคัดลอกในฐานข้อมูล Azure SQL
ที่มา
| ชื่อ | คำอธิบาย | ค่า | ต้องระบุ | คุณสมบัติสคริปต์ JSON |
|---|---|---|---|---|
| การเชื่อมต่อ | การเชื่อมต่อของคุณกับที่เก็บข้อมูลต้นทาง | <การเชื่อมต่อของคุณ> | ใช่ | การเชื่อมต่อ |
| ชนิดการเชื่อมต่อ | ชนิดการเชื่อมต่อของคุณ เลือก ฐานข้อมูล Azure SQL | ฐานข้อมูล Azure SQL | ใช่ | / |
| ตาราง | ตารางข้อมูลต้นทางของคุณ | <ชื่อตารางปลายทางของคุณ> | ใช่ | schema ตาราง |
| ใช้คิวรี | คิวรี SQL แบบกําหนดเองเพื่ออ่านข้อมูล | •ไม่มีใคร •สอบถาม • ขั้นตอนที่เก็บไว้ |
ไม่ใช่ | • sqlReaderQuery • sqlReaderStoredProcedureName, storedProcedureParameters |
| การหมดเวลาของคิวรี | การหมดเวลาสําหรับการดําเนินการคําสั่งแบบสอบถาม ค่าเริ่มต้นคือ 120 นาที | timespan | ไม่ใช่ | queryTimeout |
| ระดับการแยก | ระบุลักษณะการล็อกธุรกรรมสําหรับแหล่งข้อมูล SQL | •ไม่มีใคร • อ่านมุ่งมั่น • อ่านไม่ผูกมัด • ทําซ้ําได้อ่าน • อนุกรมได้ •ภาพถ่าย |
ไม่ใช่ | isolationLevel |
| ตัวเลือกพาร์ติชัน | ตัวเลือกการแบ่งพาร์ติชันข้อมูลที่ใช้ในการโหลดข้อมูลจากฐานข้อมูล Azure SQL | •ไม่มีใคร •พาร์ติชันทางกายภาพของตาราง • ช่วงไดนามิก |
ไม่ใช่ | partitionOption: • PhysicalPartitionsOfTable • ไดนามิกเรนจ์ |
| คอลัมน์เพิ่มเติม | เพิ่มคอลัมน์ข้อมูลเพิ่มเติมเพื่อจัดเก็บเส้นทางสัมพัทธ์หรือค่าคงที่ของไฟล์ต้นฉบับ นิพจน์ได้รับการสนับสนุนสําหรับรุ่นหลัง | •ชื่อ •ค่า |
ไม่ใช่ | คอลัมน์เพิ่มเติม: •ชื่อ •ค่า |
จุดหมาย
| ชื่อ | คำอธิบาย | ค่า | ต้องระบุ | คุณสมบัติสคริปต์ JSON |
|---|---|---|---|---|
| การเชื่อมต่อ | การเชื่อมต่อของคุณไปยังที่เก็บข้อมูลปลายทาง | <การเชื่อมต่อของคุณ > | ใช่ | การเชื่อมต่อ |
| ชนิดการเชื่อมต่อ | ชนิดการเชื่อมต่อของคุณ เลือก ฐานข้อมูล Azure SQL | ฐานข้อมูล Azure SQL | ใช่ | / |
| ตาราง | ตารางข้อมูลปลายทางของคุณ | <ชื่อตารางปลายทางของคุณ> | ใช่ | schema ตาราง |
| พฤติกรรมการเขียน | กําหนดลักษณะการเขียนเมื่อแหล่งที่มาเป็นไฟล์จากที่เก็บข้อมูลแบบไฟล์ | •สอด • อัพเซิร์ต • ขั้นตอนที่เก็บไว้ |
ไม่ใช่ | เขียนพฤติกรรม: •สอด • อัพเซิร์ต • sqlWriterStoredProcedureName, sqlWriterTableType, storedProcedureParameters |
| ล็อคโต๊ะแทรกจํานวนมาก | ใช้การตั้งค่านี้เพื่อปรับปรุงประสิทธิภาพการคัดลอกในระหว่างการดําเนินการแทรกจํานวนมากบนตารางที่ไม่มีดัชนีจากไคลเอ็นต์หลายตัว | ใช่ หรือ ไม่ | ไม่ใช่ | sqlWriterUseTableLock: จริง หรือ เท็จ |
| ตัวเลือกตาราง | ระบุว่าจะสร้างตารางปลายทางโดยอัตโนมัติหรือไม่หากไม่มีอยู่ตาม Schema ต้นทาง | •ไม่มีใคร •สร้างตารางอัตโนมัติ |
ไม่ใช่ | tableOption: •สร้างอัตโนมัติ |
| สคริปต์สําเนาล่วงหน้า | สคริปต์สําหรับกิจกรรมการคัดลอกที่จะดําเนินการก่อนที่จะเขียนข้อมูลลงในตารางปลายทางในการเรียกใช้แต่ละครั้ง คุณสามารถใช้คุณสมบัตินี้เพื่อล้างข้อมูลที่โหลดไว้ล่วงหน้า |
<สคริปต์คัดลอกล่วงหน้า> (สตริง) |
ไม่ใช่ | preCopyScript |
| การหมดเวลาชุดการเขียน | เวลารอให้การดําเนินการแทรกแบทช์เสร็จสิ้นก่อนที่จะหมดเวลา ค่าที่อนุญาตคือช่วงเวลา ค่าเริ่มต้นคือ "00:30:00" (30 นาที) | timespan | ไม่ใช่ | writeBatchTimeout |
| เขียนขนาดแบทช์ | จํานวนแถวที่จะแทรกลงในตาราง SQL ต่อชุดงาน โดยค่าเริ่มต้น บริการจะกําหนดขนาดชุดงานที่เหมาะสมแบบไดนามิกตามขนาดแถว |
<จํานวนแถว> (จํานวนเต็ม) |
ไม่ใช่ | เขียนขนาดแบทช์ |
| การเชื่อมต่อพร้อมกันสูงสุด | ขีดจํากัดบนของการเชื่อมต่อพร้อมกันที่สร้างขึ้นไปยังที่เก็บข้อมูลระหว่างการเรียกใช้กิจกรรม ระบุค่าเมื่อคุณต้องการจํากัดการเชื่อมต่อที่เกิดขึ้นพร้อมกันเท่านั้น |
<ขีดจํากัดบนของการเชื่อมต่อพร้อมกัน> (จํานวนเต็ม) |
ไม่ใช่ | max การเชื่อมต่อพร้อมกัน |
| ปิดใช้งานการวิเคราะห์เมตริกประสิทธิภาพ | การตั้งค่านี้ใช้เพื่อรวบรวมเมตริก เช่น DTU, DWU, RU และอื่นๆ สําหรับการเพิ่มประสิทธิภาพการคัดลอกและคําแนะนํา หากคุณกังวลเกี่ยวกับลักษณะการทํางานนี้ ให้เลือกกล่องกาเครื่องหมายนี้ | เลือกหรือยกเลิกการเลือก | ไม่ใช่ | disableMetricsCollection: จริง หรือ เท็จ |