Span 对象是跟踪数据模型中的基本构建基块。 它充当一个容器,用于存储关于追踪各个步骤的信息,例如 LLM 调用、工具执行、检索操作等。
跨度在跟踪中分层组织,以表示应用程序的执行流。 每个区段捕捉:
- 输入和输出数据
- 计时信息(开始和结束时间)
- 状态(成功或错误)
- 有关操作的元数据和属性
- 与其他跨度的关系(父子连接)
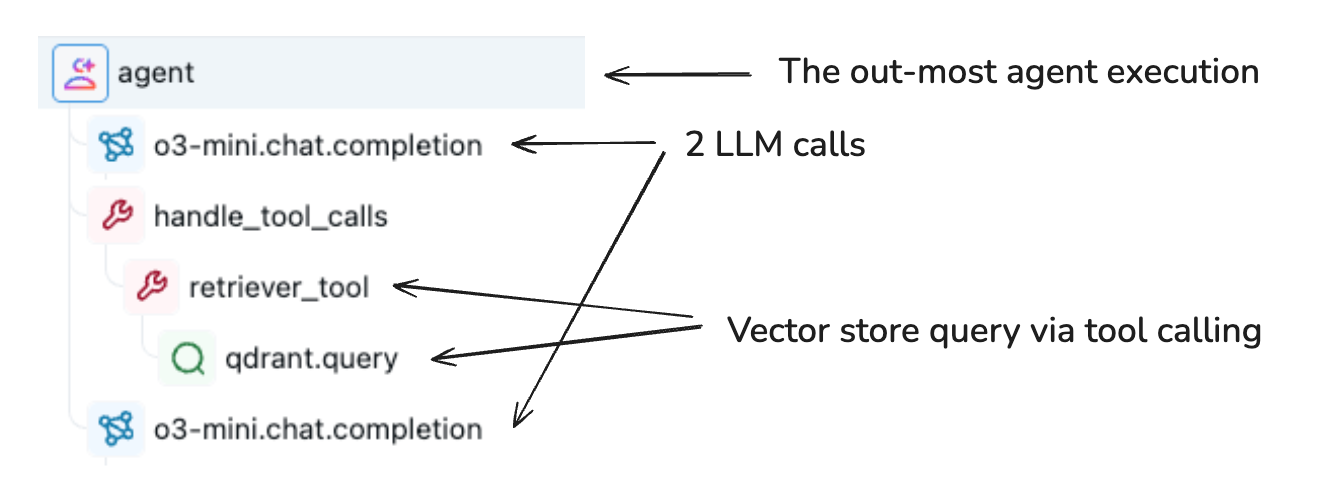
Span 对象架构
MLflow 的 Span 设计与 OpenTelemetry 规范保持兼容性。 架构包括 11 个核心属性:
| 资产 | 类型 | Description |
|---|---|---|
span_id |
str |
追踪中此区段的唯一标识符 |
trace_id |
str |
链接跨度到其父追踪 |
parent_id |
Optional[str] |
建立分层关系;None 根跨度 |
name |
str |
用户定义的或自动生成的跨度名称 |
start_time_ns |
int |
跨度开始时的 Unix 时间戳(纳秒) |
end_time_ns |
int |
跨度结束时的 Unix 时间戳(纳秒) |
status |
SpanStatus |
跨度状态: OK、 UNSET或 ERROR 具有可选说明 |
inputs |
Optional[Any] |
输入此操作的数据 |
outputs |
Optional[Any] |
输出从该操作生成的数据 |
attributes |
Dict[str, Any] |
提供行为见解的元数据键值对 |
events |
List[SpanEvent] |
系统级异常和堆栈跟踪信息 |
有关完整详细信息,请参阅 MLflow API 参考。
Span 属性
属性是键值对,用于深入了解函数和方法调用的行为修改。 它们捕获有关操作配置和执行上下文的元数据。
可以添加特定于平台的属性,例如 Unity 目录信息、 提供终结点详细信息的模型 和 基础结构元数据 ,以提高可观测性。
LLM 调用的示例 set_attributes() :
span.set_attributes({
"ai.model.name": "claude-3-5-sonnet-20250122",
"ai.model.version": "2025-01-22",
"ai.model.provider": "anthropic",
"ai.model.temperature": 0.7,
"ai.model.max_tokens": 1000,
})
范围类型
MLflow 提供用于分类的 SpanType 预定义值。 您还可以使用自定义字符串值用于专门的操作。
| 类型 | Description |
|---|---|
CHAT_MODEL |
查询聊天模型(专用 LLM 交互) |
CHAIN |
操作链 |
AGENT |
自主代理操作 |
TOOL |
工具的执行(通常由代理程序完成),例如搜索查询 |
EMBEDDING |
文本嵌入操作 |
RETRIEVER |
上下文检索操作,例如矢量数据库查询 |
PARSER |
解析操作将文本转换为结构化格式 |
RERANKER |
按相关性对上下文重新排序 |
MEMORY |
将内存操作的上下文持久化到长期存储中 |
UNKNOWN |
未指定其他类型时的默认类型 |
设置跨度类型
将 span_type 参数与修饰器或上下文管理器配合使用来设置 SpanType:
import mlflow
from mlflow.entities import SpanType
# Using a built-in span type
@mlflow.trace(span_type=SpanType.RETRIEVER)
def retrieve_documents(query: str):
...
# Using a custom span type
@mlflow.trace(span_type="ROUTER")
def route_request(request):
...
# With context manager
with mlflow.start_span(name="process", span_type=SpanType.TOOL) as span:
span.set_inputs({"data": data})
result = process_data(data)
span.set_outputs({"result": result})
按类型搜索范围
使用 MLflow search_spans()以编程方式进行查询:
import mlflow
from mlflow.entities import SpanType
trace = mlflow.get_trace("<trace_id>")
retriever_spans = trace.search_spans(span_type=SpanType.RETRIEVER)
还可以在查看跟踪时按 MLflow UI 中的范围类型进行筛选。
活动中与已完成的时间段
活动 span 或 LiveSpan 是指正在主动记录的 span,例如在由@mlflow.trace 修饰的函数或span 上下文管理器中。 一旦修饰的函数或上下文管理器退出,范围就会完成,并变为不可变 Span。
若要修改活动的跨度,请使用 mlflow.get_current_active_span() 获取对跨度的引用。
RETRIEVER span 架构
RETRIEVER 范围类型处理涉及从数据存储中检索数据的操作,例如查询向量存储中的文档。 此范围类型具有特定的输出架构,可实现增强的 UI 功能和评估功能。 输出应是文档列表,其中每个文档都是一个字典,其中包含:
-
page_content(str):检索到的文档区块的文本内容 -
metadata(Optional[Dict[str, Any]]):其他元数据,包括:-
doc_uri(str):文档源 URI。 在 Databricks 上使用 矢量搜索 时,RETRIEVER 范围可以在元数据中包含 Unity 目录卷路径,doc_uri以便进行完整世系跟踪。 -
chunk_id(str):标识文档是否为较大分块文档的一部分
-
-
id(Optional[str]):文档区块的唯一标识符
MLflow Document 实体 有助于构造此输出结构。
示例实现:
import mlflow
from mlflow.entities import SpanType, Document
def search_store(query: str) -> list[tuple[str, str]]:
# Simulate retrieving documents from a vector database
return [
("MLflow Tracing helps debug GenAI applications...", "docs/mlflow/tracing_intro.md"),
("Key components of a trace include spans...", "docs/mlflow/tracing_datamodel.md"),
("MLflow provides automatic instrumentation...", "docs/mlflow/auto_trace.md"),
]
@mlflow.trace(span_type=SpanType.RETRIEVER)
def retrieve_relevant_documents(query: str):
docs = search_store(query)
span = mlflow.get_current_active_span()
# Set outputs in the expected format
outputs = [
Document(page_content=doc, metadata={"doc_uri": uri})
for doc, uri in docs
]
span.set_outputs(outputs)
return docs
# Usage
user_query = "MLflow Tracing benefits"
retrieved_docs = retrieve_relevant_documents(user_query)