跟踪是一种可观测性技术,它通过应用程序捕获请求的完整执行流。 与传统记录隔离事件的日志不同,跟踪会创建一个详细的映射,展示数据如何流经系统,并记录沿途的每个操作。
对于 GenAI 应用程序,跟踪至关重要,因为这些系统涉及具有多个组件(LLM、检索器、工具、代理)的复杂多步骤工作流,这些组件难以调试,且无法完全查看执行流。
跟踪结构
MLflow Trace 包括两个主要对象:
Trace.info类型TraceInfo:说明跟踪的起源、状态和执行时间的元数据。 包括用于搜索或筛选跟踪的其他上下文的 标记 ,例如用户、会话和开发人员提供的键值对。Trace.data类型TraceData:包含仪器化的 Span 对象的实际载荷,这些对象捕获应用程序从输入到输出的每一步执行。

MLflow 跟踪与 OpenTelemetry 规范兼容,这是一种广泛使用的可观测性行业标准。 这可确保与其他可观测性工具的互作性,而 MLflow 使用特定于 GenAI 的结构和属性增强了 OpenTelemetry 模型。
TraceInfo
TraceInfo 提供有关总体跟踪的轻量级元数据。 关键字段包括:
| 领域 | Description |
|---|---|
trace_id |
跟踪的唯一标识符 |
trace_location |
存储追踪的位置(MLflow 试验或 Databricks 推理表) |
request_time |
跟踪的开始时间(以毫秒为单位) |
state |
跟踪状态:OK、、ERRORIN_PROGRESS或STATE_UNSPECIFIED |
execution_duration |
跟踪持续时间(以毫秒为单位) |
request_preview |
输入的 JSON 编码预览(根跨度输入) |
response_preview |
输出的 JSON 编码预览(根范围输出) |
tags |
用于筛选和搜索追踪的键值对 |
TraceData
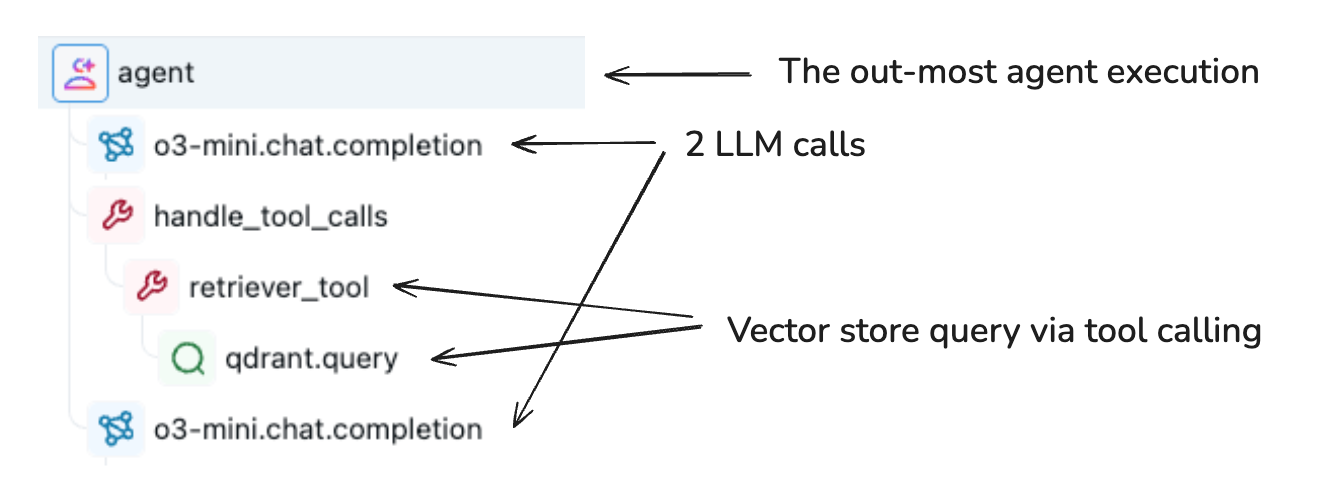
该 TraceData 对象是 Span 对象的容器,其中存储执行详细信息。 每个跨度捕获与特定操作有关的信息,包括:
- 请求和响应
- 延迟测量
- LLM 消息和工具参数
- 检索的文档和上下文
- 元数据和属性
跨度通过父-子连接形成分层结构,创建一个表示应用程序执行流程的树。
标记
标记是附加到跟踪上的可变键值对,用于组织和筛选。 MLflow 为常见用例定义标准标记:
-
mlflow.trace.session:用于对相关跟踪进行分组的会话标识符 -
mlflow.trace.user:用于跟踪每个用户交互的用户标识符 -
mlflow.source.name:生成跟踪的入口点或脚本 -
mlflow.source.git.commit:源代码的 Git 提交哈希(如果适用) -
mlflow.source.type:源类型(PROJECT等NOTEBOOK)
还可以为特定需求添加自定义标记。 在 添加上下文以跟踪 和 附加自定义标记/元数据中了解详细信息。
存储布局
MLflow 针对性能和成本优化跟踪存储。 创建 试验时,可以使用 Unity 目录卷自定义跟踪存储位置。 然后,跟踪数据访问受 Unity 目录卷特权 控制,以提高安全性和合规性。
TraceInfo 作为具有索引字段的单行直接存储在关系数据库中,从而实现用于搜索和筛选跟踪的快速查询。
TraceData (Spans) 存储于项目存储中,而不是存储在数据库中,因为它的大小较大。 这样就可以对大型跟踪卷进行经济高效的处理,对查询的性能影响最小。
活动跟踪与已完成跟踪
活动跟踪是被主动记录的跟踪,例如在修饰的@mlflow.trace函数中。 装饰函数退出后,追踪已完成,但仍可使用新数据进行注释。
使用活动跟踪或最近跟踪的重要方法包括 mlflow.get_active_trace_id() 和 mlflow.get_last_active_trace_id()。