本教程介绍如何在 Microsoft Fabric 中创建 Apache Spark 作业定义。
Spark 作业定义创建过程快速简单;有几种方法来助你开始。
可以从 Fabric 门户或使用 Microsoft Fabric REST API 创建 Spark 作业定义。 本文重点介绍如何从 Fabric 门户创建 Spark 作业定义。 有关使用 REST API 创建 Spark 作业定义的信息,请参阅 Apache Spark 作业定义 API v1 和 Apache Spark 作业定义 API v2。
先决条件
准备事项:
- 具有有效订阅的 Fabric 租户帐户。 免费创建帐户。
- Microsoft Fabric 中的工作区。 有关更多信息,请参阅 在 Microsoft Fabric 中创建和管理工作区。
- 工作区中至少有一个湖屋。 Lakehouse 充当 Spark 作业定义的默认文件系统。 有关详细信息,请参阅 创建 lakehouse。
- Spark 作业的主定义文件。 此文件包含应用程序逻辑,必须运行 Spark 作业。 每个 Spark 作业定义只能有一个主定义文件。
创建 Spark 作业定义时,需要为它指定一个名称。 此名称在当前工作区中必须是唯一的。 新的 Spark 作业定义是在当前工作区中创建的。
在 Fabric 门户中创建 Spark 作业定义
若要在 Fabric 门户中创建 Spark 作业定义,请执行以下步骤:
- 登录到 Microsoft Fabric 门户。
- 导航到要在其中创建 Spark 作业定义的所需工作区。
- 选择 “新建项”>Spark 任务定义。
- 在 “新建 Spark 作业定义 ”窗格中,提供以下信息:
- 名称:输入 Spark 作业定义的唯一名称。
- 位置:选择工作区位置。
- 选择 “创建 ”以创建 Spark 作业定义。
创建 Spark 作业定义的备用入口点是使用 Fabric 主页上的 SQL ... 磁贴进行数据分析。 可以通过选择“常规”磁贴找到相同的选项。

选择磁贴时,系统会提示创建新的工作区或选择现有工作区。 选择工作区后,将打开 Spark 作业定义创建页。
自定义 PySpark 的 Spark 作业定义(Python)
在为 PySpark 创建 Spark 作业定义之前,您需要将一个示例 Parquet 文件上传到 lakehouse。
- 下载示例 Parquet 文件 yellow_tripdata_2022-01.parquet。
- 请前往您想要上传文件的 Lakehouse。
- 将其上传到 Lakehouse 的“文件”部分。
若要为 PySpark 创建 Spark 作业定义,请执行以下操作:
从“语言”下拉列表中选择“PySpark (Python)”。
下载 createTablefromParquet.py 示例定义文件。 将其作为主定义文件上传。 主要定义文件 (job.Main) 包含应用程序逻辑,必须具有它才能运行 Spark 作业。 每个 Spark 作业定义只能上传一个主要定义文件。
注意
可以从本地桌面上传主要定义文件,还可通过提供文件的完整 ABFSS 路径来从现有 Azure Data Lake Storage (ADLS) Gen2 上传。 例如,
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path。(可选)将引用文件上传为
.py(Python) 文件。 引用文件是主定义文件导入的 python 模块。 与主要定义文件一样,可以从桌面或现有的 ADLS Gen2 上传。 支持多个引用文件。提示
如果使用 ADLS Gen2 路径,请确保该文件可访问。 必须向运行作业的用户帐户提供对存储帐户的适当权限。 可通过以下两种不同的方式授予权限:
- 为用户帐户分配存储帐户的参与者角色。
- 通过 ADLS Gen2 访问控制列表 (ACL) 向用户帐户授予对文件的读取和执行权限。
对于手动运行,当前已登录用户的帐户用于运行作业。
如果需要,请为作业提供命令行参数。 使用空格作为拆分器来分隔参数。
将湖屋引用添加到作业。 必须向作业添加至少一个湖屋引用。 此湖屋是作业的默认湖屋上下文。
支持多个湖屋引用。 可在“Spark 设置”页面上找到非默认湖屋名称和完整 OneLake URL。


自定义 Scala/Java 的 Spark 作业定义
若要为 Scala/Java 创建 Spark 作业定义,请执行以下操作:
从“语言”下拉列表中选择“Spark(Scala/Java)”。
将主定义文件作为
.jar(Java) 文件上传。 主要定义文件包含此作业的应用程序逻辑,必须具有它才能运行 Spark 作业。 每个 Spark 作业定义只能上传一个主要定义文件。 提供主类名。(可选)将引用文件上传为
.jar(Java) 文件。 引用文件是主定义文件引用/导入的文件。如果需要,请为作业提供命令行参数。
将湖屋引用添加到作业。 必须向作业添加至少一个湖屋引用。 此湖屋是作业的默认湖屋上下文。
自定义 R 的 Spark 作业定义
若要为 SparkR(R) 创建 Spark 作业定义,请执行以下操作:
从“语言”下拉列表中选择“SparkR (R)”。
将主定义文件作为
.r(R) 文件上传。 主要定义文件包含此作业的应用程序逻辑,必须具有它才能运行 Spark 作业。 每个 Spark 作业定义只能上传一个主要定义文件。(可选)将引用文件上传为
.r(R) 文件。 引用文件是主要定义文件引用/导入的文件。如果需要,请为作业提供命令行参数。
将湖屋引用添加到作业。 必须向作业添加至少一个湖屋引用。 此湖屋是作业的默认湖屋上下文。
注意
Spark 作业定义是在当前工作区中创建的。
用于自定义 Spark 作业定义的选项
有几个选项来进一步自定义 Spark 作业定义的执行。
Spark 计算:在 Spark 计算 选项卡中,可以看到用于运行 Spark 作业的 Fabric 运行时版本 。 还可以查看用于运行作业的 Spark 配置设置。 可以通过选择 “添加 ”按钮来自定义 Spark 配置设置。
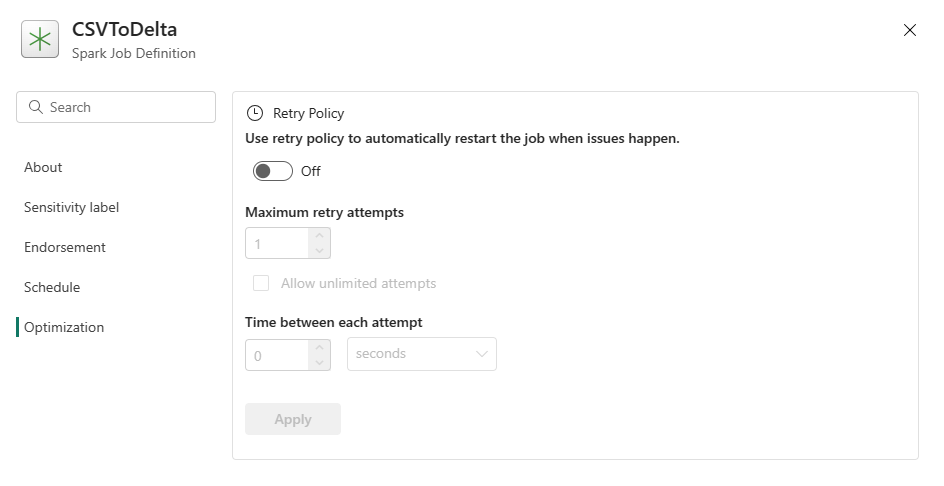
优化:在“优化”选项卡中,可为作业启用并设置“重试策略”。 启用后,如果作业运行失败,会重新尝试运行。 还可以设置最大重试次数和重试间隔。 每次尝试重试时,都会重启作业。 确保作业是幂等的。