Hinweis
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, sich anzumelden oder das Verzeichnis zu wechseln.
Für den Zugriff auf diese Seite ist eine Autorisierung erforderlich. Sie können versuchen, das Verzeichnis zu wechseln.
Mit Copilot Studio können Sie Ihre Agents mit domänenspezifischem Wissen ausstatten, das auf denselben vertrauenswürdigen, vertrauten Datenquellen basiert, die Sie über Power Platform-Konnektoren aufgebaut haben.
Indem Sie externe Inhalte von Ihrem Gerät, OneDrive oder SharePoint hochladen, können Sie Ihre Agents mit kontextbezogenem Wissen erweitern, das auf Ihr Unternehmen zugeschnitten ist. Diese Dateien werden sicher in Microsoft Dataverse gespeichert und automatisch in semantische Indizes und Vektoreinbettungen verarbeitet. Mit dieser Konfiguration können Ihre Agents präzisere, geerdete Antworten basierend auf den von Ihnen bereitgestellten Informationen generieren.
Dateien, die in Copilot Studio hochgeladen wurden, verwenden Microsoft Dataverse, um Rohdateien aufzunehmen, um Indizes und Vektoreinbettungen zu erstellen, mit denen Qualitätsantworten für Ihre Agents bereitgestellt werden. Diese Dateien können von Ihrem Computer hochgeladen oder eine Verbindung mit OneDrive oder SharePoint hergestellt werden.
Das Hochladen von Dateien als Wissensquellen unterstützt Entwickler dabei, ihre Agents mit zusätzlichen Daten anzureichern, das Wissen des Sprachmodells zu erweitern und den Agent mit spezifischen Informationen zu versorgen, die vom Entwickler bereitgestellt werden. Entwickler können verschiedene Dateien hochladen, die semantisch als Vektoreinbettungen indiziert und dann als Wissen für Agents verwendet werden. Dieses Wissen, das in Agents verwendet wird, kann dann mit authentifizierten und nicht authentifizierten Benutzern des Agents geteilt werden.
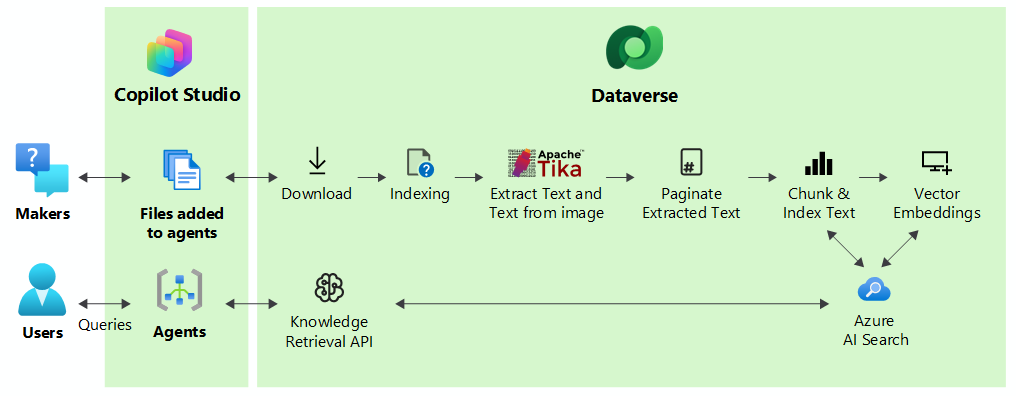
Um die Antworten des Agents zu verbessern, werden hochgeladene Dateien in Teile unterteilt, um eine schnellere Verarbeitung und eine Vektorindizierung zu ermöglichen, um semantische Übereinstimmungen mit der Abfrage des Benutzers bereitzustellen. Die Dateien werden sicher in Dataverse gespeichert. Wenn ein Benutzer eine Anfrage über einen Agent stellt, ermittelt Copilot Studio die relevantesten Teile, die der Absicht der Benutzeranfrage entsprechen, und gibt die Ergebnisse an den Benutzer zurück.
Ebenso nimmt Dataverse OneDrive-Dateien, SharePoint-Dateien (unter Verwendung der Optionen unter „Datei-Upload“) und unstrukturierte Inhalte wie Knowledge-Base-Artikel aus anderen Unternehmenssystemen wie Salesforce, ServiceNow, Confluence und ZenDesk auf, um dem Agenten bessere semantische Ergebnisse zu liefern.
Anmerkung
Weitere Informationen zur Verwendung strukturierter Daten finden Sie unter Verwenden des Code-Interpreters zum Analysieren strukturierter Daten.
Power Platform-Konnektoren für unstrukturierte Daten
Die folgenden Power Platform-Konnektoren sind für die Arbeit mit unstrukturierten Datenquellen konfiguriert:
OneDrive
One Drive ermöglicht es Entscheidungsträgern, eine Dateiauswahlschnittstelle zu verwenden, um die Dateien und Ordner auszuwählen, die sie einbeziehen möchten. Nach der Auswahl werden die Elemente in Dataverse abgerufen und zur Verwendung indiziert. Zu den hinzugefügten Ordnern gehören alle unterstützten Dateien und Unterordner innerhalb dieses Ordners bis zum Gesamtdateilimit.
SharePoint
Mit SharePoint-Dokumenten können Entwickler über eine Auswahl-Schnittstelle die Dateien und Ordner auswählen, die sie einfügen möchten. Nach der Auswahl werden die Elemente in Dataverse abgerufen und zur Verwendung indiziert. Zu den hinzugefügten Ordnern gehören alle unterstützten Dateien und Unterordner innerhalb dieses Ordners bis zum Gesamtdateilimit. Derzeit werden Seiten nicht unterstützt.
Salesforce
Der Salesforce-Konnektor für unstrukturierte Daten unterstützt die Möglichkeit, Wissensdatenbanken mit Wissensartikeln abzurufen. Entwickler wählen eine Wissensdatenbank aus, und alle Artikel in dieser Wissensdatenbank werden für die Verwendung indiziert. Einzelne Artikel oder Themen können nicht ausgewählt werden. Beim Abfragen von Daten gibt es keine Möglichkeit, einen bestimmten Artikel oder Wissensdatenbank anzugeben. In der Liste Wissen wird ein einzelnes Objekt für alle Wissensobjekte angezeigt, die Sie beim Erstellen der Quelle auswählen.
ServiceNow
Der ServiceNow-Konnektor für unstrukturierte Daten unterstützt die Möglichkeit, Wissensdatenbanken mit Wissensartikeln abzurufen. Wissensdatenbanken enthalten Artikel. Entwickler wählen eine Wissensdatenbank aus, und alle Artikel in dieser Wissensdatenbank werden für die Verwendung indiziert. Einzelne Artikel können nicht ausgewählt werden. Bei der Abfrage von Daten besteht keine Möglichkeit, eine Wissensdatenbank, einen Ordner oder einen einzelnen Artikel anzugeben. In der Liste Wissen wird ein einzelnes Objekt für alle Wissensobjekte angezeigt, die Sie beim Erstellen der Quelle auswählen.
Confluence
Der Confluence-Konnektor für unstrukturierte Daten unterstützt die Möglichkeit, die Leerzeichen abzurufen, die Seiten enthalten, Unterordner werden ebenfalls unterstützt. Einzelne Seiten können nicht ausgewählt werden. Beim Abfragen von Daten gibt es keine Möglichkeit, eine Seite anzugeben. Die Wissensliste zeigt ein einzelnes Objekt für alle Seiten innerhalb des Leerzeichens an.
Zendesk
Der Zendesk-Konnektor für unstrukturierte Daten unterstützt die Möglichkeit, die Wissensdatenbank mit Wissensartikeln abzurufen. Einzelne Artikel, Kategorien oder Abschnitte können nicht ausgewählt werden. Beim Abfragen von Daten gibt es keine Möglichkeit, einen Artikel, eine Kategorie oder einen Abschnitt anzugeben. Die Wissensliste zeigt ein einzelnes Objekt für alle Artikel innerhalb der Wissensdatenbank.
Sicherheit
Wenn ein Benutzer einen Agent abfragt, der eine Power Platform-Konnektor-Quelle verwendet, werden einige Autorisierungsprüfungen durchgeführt.
Konnektor-Zugriff
Wenn ein Entwickler zum ersten Mal eine konnektorbasierte Quelle verwendet, wird er gebeten, entweder einen vorhandenen Power Platform-Konnektor auszuwählen oder einen neuen hinzuzufügen. Dieser Prozess stellt sicher, dass Daten nur mit Entscheidungsträgern geteilt werden, die über die entsprechenden Berechtigungen verfügen, und den Zugriff auf die Datenquelle selbst ermöglicht.
Inhalts-Zugriff
Wenn eine Abfrage durchgeführt wird, werden die Verbindungsinformationen des Benutzers verwendet, um die Datenquelle zu überprüfen, um sicherzustellen, dass sie über die Berechtigung zum Anzeigen des Inhalts verfügen. Obwohl die Blöcke und Indizes lokal in Dataverse gespeichert sind, wird eine Live-Prüfung der Abfragen durchgeführt, um sicherzustellen, dass der aktuelle Benutzer Zugriff auf die Daten hat, bevor eine Zusammenfassung oder Antwort bereitgestellt wird.
Anmerkung
- Wenn ein Benutzer keine Berechtigungen für bestimmte Dateien oder Wissensdatenbank-Artikel besitzt, wird ihm kein Ergebnis angezeigt und er erhält die Standardmeldung „Es wurden keine Ergebnisse gefunden“. Wenn Benutzer der Meinung sind, dass es Ergebnisse für diese Quelle geben sollte, müssen sie sich an ihren Administrator wenden, um sicherzustellen, dass sie über die erforderlichen Berechtigungen für die Daten verfügen, auf die sie zugreifen möchten.
- Inhaltsberechtigungsinformationen werden nicht lokal gespeichert. Bei der Durchführung aller Berechtigungsprüfungen ist die Quelle live, um sicherzustellen, dass sie so aktuell wie möglich ist.
Synchronisierungs- und Dateiaktualisierungshäufigkeit
Verbundene Dateien aus OneDrive und SharePoint und unstrukturierte Wissensartikel werden mit einem geplanten Synchronisierungsauftrag frisch gehalten. Dieser Auftrag wird automatisch im Hintergrund ausgeführt, der Inhalt der Dateien aktualisiert und die Änderungen neu indiziert, um genaue Ergebnisse für Abfragen bereitzustellen. Aktualisierungen verwalten nicht nur Änderungen an Inhalten, sondern stellen außerdem sicher, dass alle aus der Quelle gelöschten Inhalte nicht mehr als Teil von Abfrageantworten angezeigt werden. Derzeit gibt es keine Möglichkeit, eine Aktualisierung manuell auszulösen.
Weitere Informationen zum Aktualisierungshäufigkeitszeitpunkt finden Sie unter Unstrukturierte Datenquellengrenzwerte in Copilot Studio.
Lizenzierung
Alle Anfragen, die Wissen enthalten, werden zu den Messaging-Tarifen für generative Microsoft Copilot-Antworten berechnet. Weitere Informationen finden Sie unter Abrechnungstarife und Verwaltung.
Wenn Wissensquellen Daten aufnehmen müssen, dann unterliegt die Speicherung der Daten und die entsprechenden Indizes zum Abrufen dieser Daten den Speicherberechtigungen, die der Kunde hat. Weitere Informationen zur Suche in natürlicher Sprache von Dataverse finden Sie unter Verbesserte KI-gesteuerte Funktionen bei der Dataverse-Suche.
Grenzwerte und Einschränkungen
Beim ersten Aktivieren der unstrukturierten Datenunterstützung kann es eine Verzögerung zwischen 5 und 30 Minuten für die Dataverse-Konfiguration und die Indizierung geben, bevor die hinzugefügten Dateien verarbeitet werden. Die Dauer hängt von der Größe der aktuellen Dataverse-Umgebung ab.
Jeder Agent kann maximal 500 Wissensobjekte besitzen. Diese Objekte können Dateien, Ordner, Wissensartikel, Websites oder andere Quellen sein.
Derzeit können in einem Agenten nur fünf verschiedene Quellen gleichzeitig verwendet werden. Beispielsweise SharePoint, Dataverse, OneDrive oder andere Quellen.
Weitere Informationen zu bestimmten Grenzwerten und Einschränkungen für die unterstützten unstrukturierten Datenquellen finden Sie unter Unstrukturierte Datenquellengrenzwerte in Copilot Studio.
Anmerkung
Copilot Studio-Agents erfordern die Dataverse-Suche, um diese Wissensquelle zu verwenden. Wenn Sie einem Agent keine Dataverse-fähige Datei hinzufügen können, bitten Sie Ihren Administrator, die Dataverse-Suche in Ihrer Umgebung zu aktivieren. Weitere Informationen zur Dataverse-Suche und deren Verwaltung finden Sie unter Was ist die Dataverse-Suche? und Dataverse-Suche nach Ihrer Umgebung konfigurieren.
Häufig gestellte Fragen
Das SharePoint-Symbol wird nicht im Abschnitt „Dateien hochladen“ im Dialogfeld „Wissen hinzufügen“ angezeigt?
Es gibt eine leichte Verzögerung zwischen der Installation einer Lösung und der Anzeige in allen vorhandenen Organisationen. Um eine manuelle Aktualisierung vorzunehmen, gehen Sie wie folgt vor:
- Melden Sie sich mit Ihren Administrator-Anmeldeinformationen beim Power Platform Admin Center an.
- Wählen Sie im seitlichen Navigationsbereich Verwalten aus.
- Wählen Sie aus der Liste der Produkte Dynamics 365-Apps. Es wird ein Bereich geöffnet.
- Suchen Sie nach „PowerAIExtensions“.
- Wählen Sie die drei Punkte (...) für Microsoft Dynamics 365 - PowerAIExtensions aus und wählen Sie Installieren.
- Wählen Sie im Dropdownmenü Ihre Umgebung und dann Installieren aus.
- Öffnen Sie nach Abschluss der Installation Power Apps in einem neuen Fenster.
- Wählen Sie im linken Bereich "Lösungen" aus.
- Wählen Sie Verlauf anzeigen aus.
- Suchen Sie nach „PowerAIExtensions_Anchor“, und stellen Sie sicher, dass es auf 1.01.688 oder höher festgelegt ist.
Was ist im Dialogfeld „Wissen hinzufügen“ der Unterschied zwischen den beiden SharePoint-Optionen?
Im Dialogfeld Wissen hinzufügen gibt es zwei SharePoint-Optionen. Die SharePoint-Option im Abschnitt „Dateiupload“ (1) wird verwendet, um einzelne SharePoint-Dateien oder -Ordner hochzuladen und ermöglicht Dateisynchronisierungsfunktionen. Die andere SharePoint-Option (2) bietet die vollständige Unterstützung von SharePoint in Copilot Studio.

Was geschieht, wenn ich meinem Agent mehr als 500 Wissensobjekte hinzufüge?
Sie sind daran gehindert, weitere Objekte hinzuzufügen, es sei denn, Sie löschen zuerst vorherige Objekte.
Verfügt jeder Agent über einen eigenen Index der Wissensquelle?
Wissensquellen werden in Dataverse zur Verwendung in der Umgebung gespeichert, in der sie erstellt wurden. Wenn derselbe SharePoint-Ordner in mehreren Agents verwendet wird, wird eine einzelne Instanz des Ordners für alle Agents verwendet.
Was geschieht, wenn ich einen Ordner mit mehr als der maximalen Anzahl von Dateien, Ordnern und Unterordnern beim Hinzufügen einer SharePoint- oder OneDrive-Quelle auswähle?
Copilot Studio ruft bis zur maximalen Anzahl von Dateien, Ordnern und Unterordnern ab und indiziert diese. Die restlichen Elemente werden nicht verarbeitet. Derzeit gibt es keine Meldung, die angibt, was verarbeitet wurde und was nicht.
Eine der Dateien, die ich hinzugefügt habe (oder die Teil eines Ordners war, den ich hinzugefügt habe) wird als Teil der Wissensquelle angezeigt, aber ich kann keine Antworten daraus erhalten. Warum?
Dieses Problem könnte mit einem der folgenden Gründe zusammenhängen:
- Die Datei oder der Ordner ist auf der Seite Wissen auf Bereit gesetzt.
- Stellen Sie sicher, dass der Dateiname kein nicht unterstütztes Zeichen (speziell für SharePoint-Dateien) enthält.
- Stellen Sie sicher, dass die Datei keine Vertraulichkeitseinstellungen wie Vertraulich oder Streng vertraulich haben oder mit Kennwortschutz versehen sind.
- Stellen Sie sicher, dass es sich um einen unterstützten Dateityp handelt.
- Wenn die Datei oder der Ordner von der OneDrive- oder SharePoint-Website eines anderen Benutzers stammt, überprüfen Sie, ob sie für den Hersteller freigegeben ist.
- Wenn die Datei eine Wissensdatenbankdatei ist, stellen Sie sicher, dass Ihr Konto über Berechtigungen zum Anzeigen des Inhalts im Quellsystem verfügt.