Remarque
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Azure DevOps Services fournit des outils de développement collaboratifs tels que des pipelines haute performance, référentiels Git privés gratuits, tableaux Kanban configurables et fonctionnalités de test continu et automatisé. Azure Pipelines est une fonctionnalité Azure DevOps qui vous permet de gérer CI/CD pour déployer votre code avec des pipelines haute performance fonctionnant avec n'importe quel langage, plateforme ou cloud. Azure Data Explorer - Outils de pipeline est la tâche Azure Pipelines qui vous permet de créer des pipelines de mise en production et de déployer vos modifications de base de données dans vos bases de données Azure Data Explorer. Il est disponible gratuitement dans Visual Studio Marketplace. L’extension inclut les tâches de base suivantes :
Commande Azure Data Explorer - Exécuter des commandes d’administration sur un cluster Azure Data Explorer
Requête Azure Data Explorer - Exécuter des requêtes sur un cluster Azure Data Explorer et analyser les résultats
Porte de verrouillage du serveur de requêtes Azure Data Explorer - Tâche sans agent pour contrôler les publications en fonction du résultat de la requête.
Ce document décrit un exemple simple d’utilisation de la tâche Azure Data Explorer - Pipeline Tools pour déployer des modifications de schéma dans votre base de données. Pour les pipelines CI/CD, consultez la documentation Azure DevOps.
Prérequis
- Un abonnement Azure. Créez un compte Azure gratuit.
- Un cluster et une base de données Azure Data Explorer. Créez un cluster et une base de données.
- Configuration d'un cluster Azure Data Explorer :
- Créez une application Microsoft Entra en approvisionnant une application Microsoft Entra.
- Accordez l’accès à votre application Microsoft Entra sur votre base de données Azure Data Explorer via la gestion des autorisations de la base de données Azure Data Explorer.
- Configuration d'Azure DevOps :
- Installation de l’extension :
Si vous êtes le propriétaire de l’instance Azure DevOps, installez l’extension à partir de la Place de marché, sinon contactez le propriétaire de votre instance Azure DevOps et demandez-lui de l’installer.

Préparer votre contenu pour la mise en production
Vous pouvez utiliser les méthodes suivantes pour exécuter des commandes d’administration sur un cluster au sein d’une tâche :
Utilisez un modèle de recherche pour obtenir plusieurs fichiers de commande à partir d’un dossier d’agent local (sources de build ou artefacts de mise en production).

Écrire des commandes en ligne.
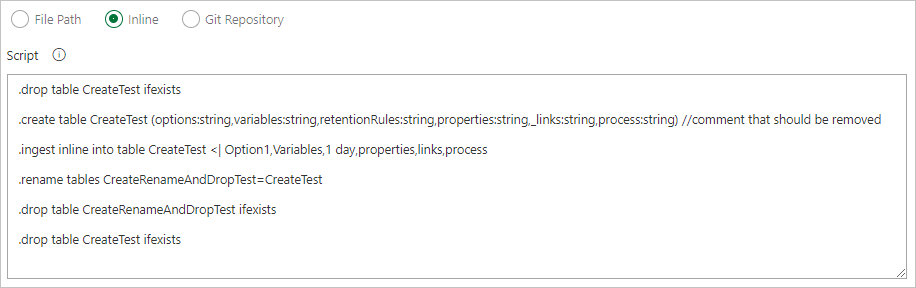
Spécifiez un chemin d’accès de fichier pour obtenir des fichiers de commande directement à partir du contrôle de code source Git (recommandé).
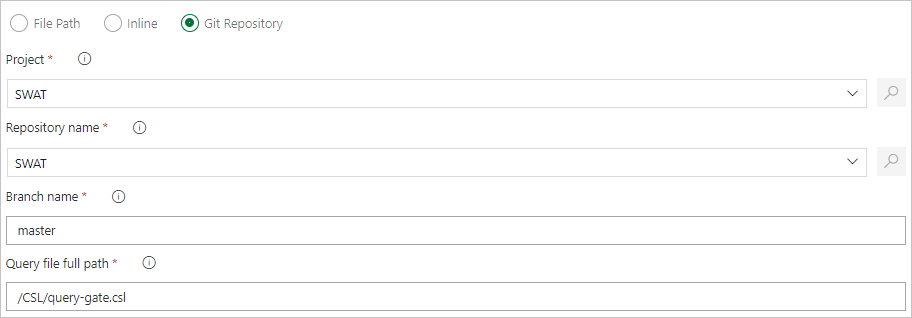
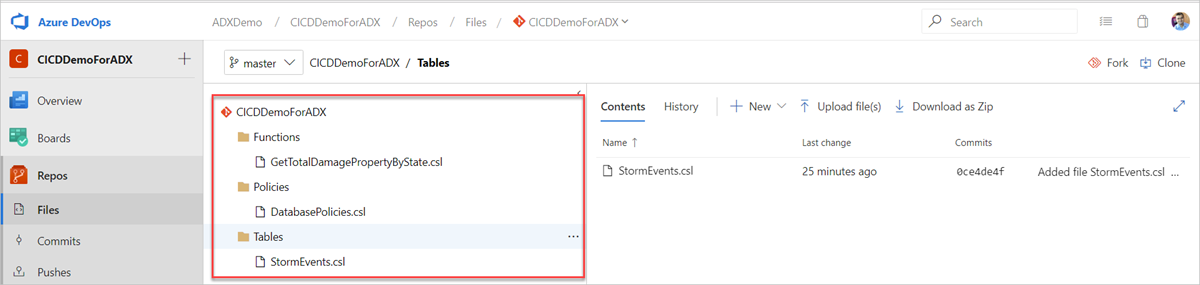
Créez les dossiers exemples suivants (Fonctions, Stratégies, Tables) dans votre référentiel Git. Copiez les fichiers du référentiel d’exemples dans les dossiers respectifs et validez les modifications. Les fichiers exemples sont fournis pour exécuter le workflow suivant.
Conseil
Lorsque vous créez votre propre workflow, nous vous recommandons de rendre votre code idempotent. Par exemple, utilisez
.create-merge tableau lieu de.create table, et utilisez la fonction.create-or-alterau lieu de la fonction.create.
Créer un pipeline de mise en production
Connectez-vous à votre organisation Azure DevOps.
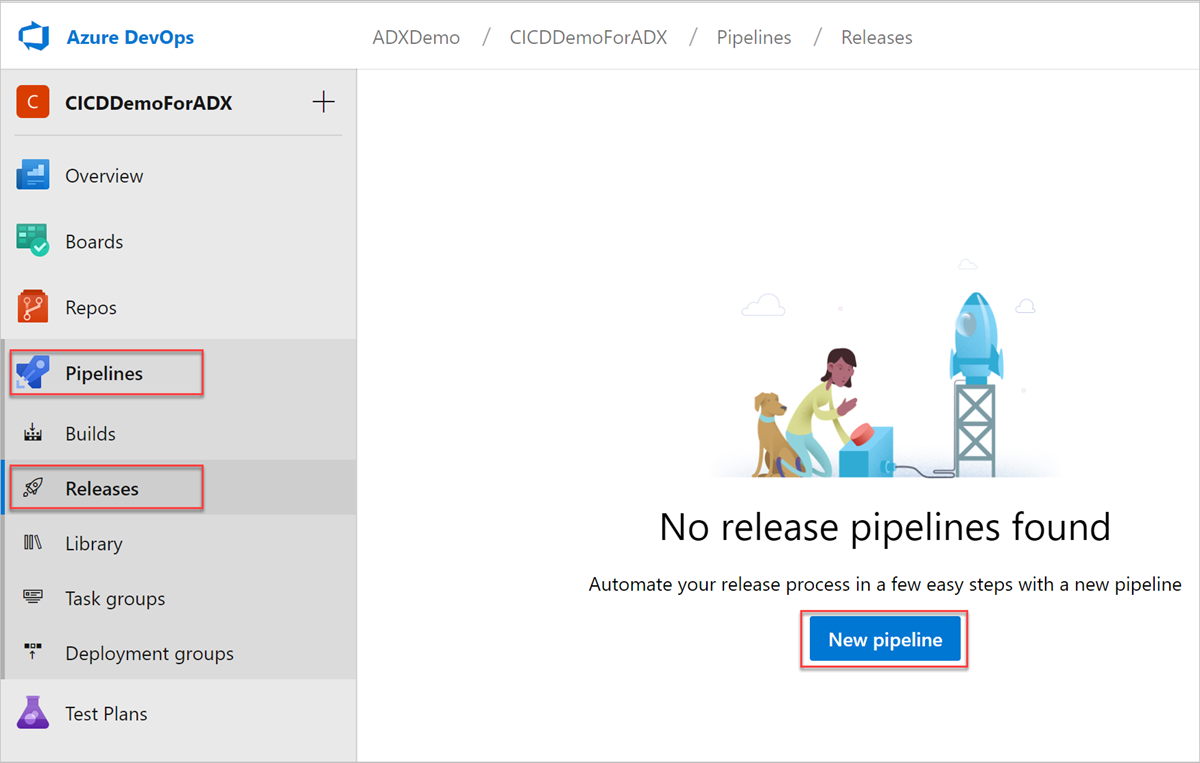
Sélectionnez Pipelines Releases> dans le menu de gauche, puis sélectionnez Nouveau pipeline.
La fenêtre Nouveau pipeline de mise en production s'ouvre. Dans l'onglet Pipelines, sous le volet Sélectionner un modèle, sélectionnez Projet vide.
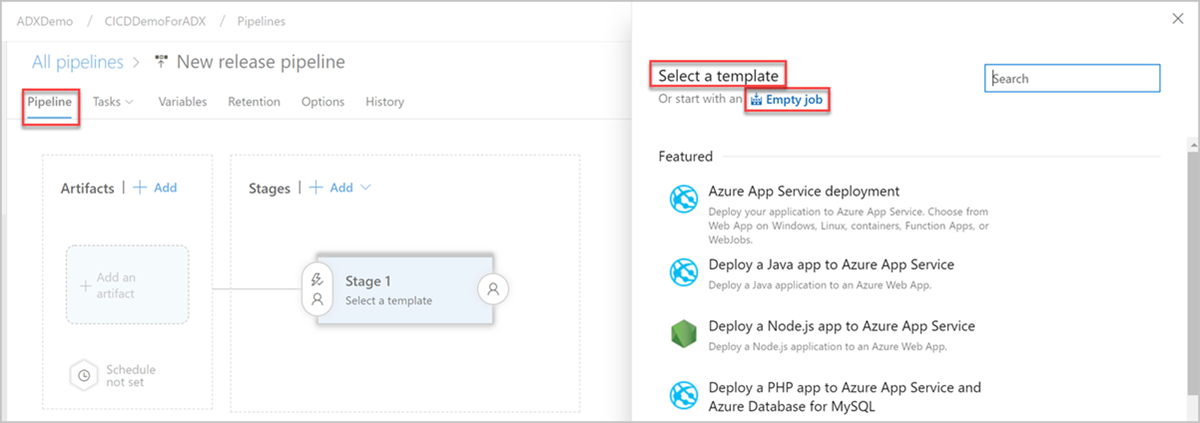
Sélectionnez le bouton Étape . Dans le volet Étape , ajoutez le nom de l’étape, puis sélectionnez Enregistrer pour enregistrer votre pipeline.
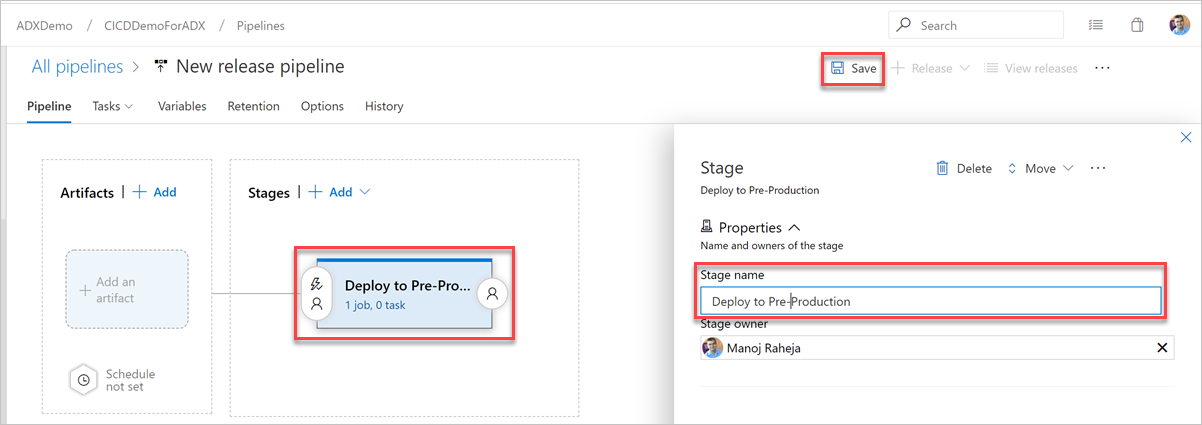
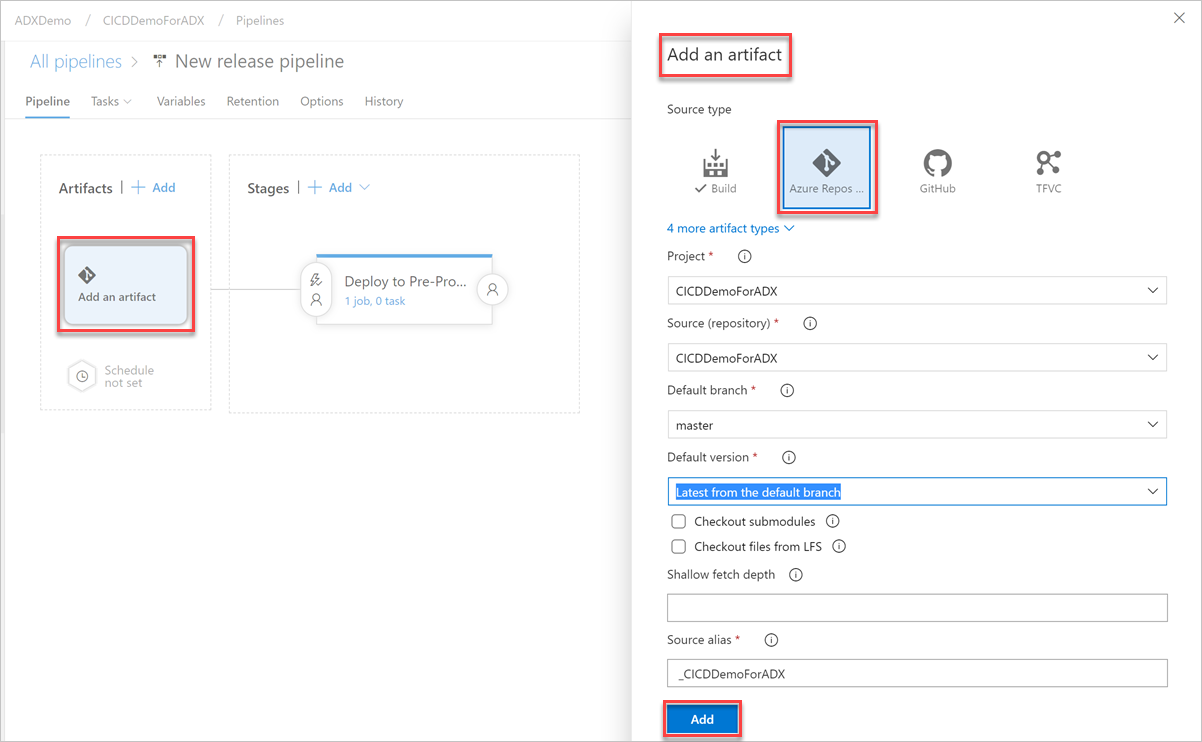
Sélectionnez le bouton Ajouter un artefact. Dans le volet Ajouter un artefact, sélectionnez le référentiel où se trouve votre code, renseignez les informations pertinentes, puis cliquez sur Ajouter. Sélectionnez Enregistrer pour enregistrer votre pipeline.
Dans l’onglet Variables , sélectionnez + Ajouter pour créer une variable pour l’URL de point de terminaison utilisée dans la tâche. Entrez le nom et la valeur du point de terminaison, puis sélectionnez Enregistrer pour enregistrer votre pipeline.

Pour rechercher votre URL de point de terminaison, accédez à la page de présentation de votre cluster Azure Data Explorer, dans le portail Azure, et copiez l’URI du cluster. Construisez l’URI de la variable au format suivant
https://<ClusterURI>?DatabaseName=<DBName>. Par exemple, https://kustodocs.westus.kusto.windows.net?DatabaseName=SampleDB
Créer une tâche pour déployer les dossiers
Sous l’onglet Pipeline , sélectionnez 1 travail, 0 tâche à ajouter.
Répétez les étapes suivantes pour créer des tâches de commande afin de déployer des fichiers à partir des dossiers Tables, FonctionsStratégies :
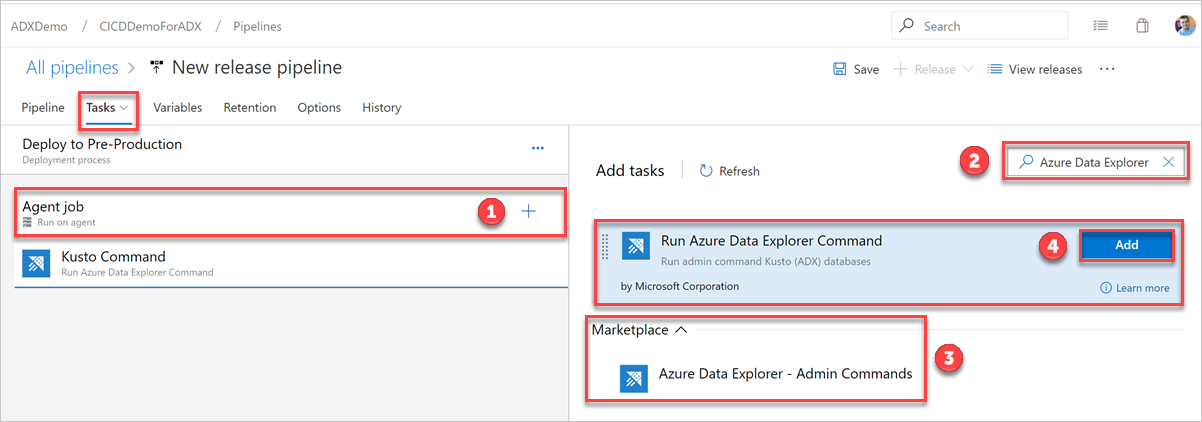
Sous l’onglet Tâches, sélectionnez + par Travail d’agent et recherchez Azure Data Explorer.
Sous Exécuter la commande Azure Data Explorer, sélectionnez Ajouter.
Sélectionnez Commande Kusto et mettez à jour la tâche avec les informations suivantes :
Nom d’affichage : nom de la tâche. Par exemple,
Deploy <FOLDER>où<FOLDER>est le nom du dossier pour la tâche de déploiement que vous créez.Chemin d’accès au fichier : pour chaque dossier, spécifiez le chemin au format
*/<FOLDER>/*.csl, où<FOLDER>est le dossier approprié pour la tâche.URL de point de terminaison : spécifiez la variable
EndPoint URLcréée à l’étape précédente.Utiliser le point de terminaison de service : sélectionnez cette option.
Point de terminaison de service : sélectionnez un point de terminaison de service existant ou créez-en un (+ Nouveau) en fournissant les informations suivantes dans la fenêtre Ajouter une connexion au service Azure Data Explorer :
Setting Valeur suggérée Méthode d’authentification Configurez les informations d’identification d’identité fédérées (FIC) (recommandé) ou sélectionnez l’authentification par principal de service (SPA). Nom de connexion Entrer un nom pour identifier ce point de terminaison de service URL du cluster La valeur se trouve dans la section Vue d'ensemble de votre cluster Azure Data Explorer dans le portail Azure ID de principal de service Entrez l’ID d’application Microsoft Entra (créé en tant que prérequis) Clé d'application du principal de service Entrez la clé d’application Microsoft Entra (créée en tant que prérequis) ID de locataire Microsoft Entra Entrez votre locataire Microsoft Entra (par exemple, microsoft.com ou contoso.com)
Cochez la case Autoriser tous les pipelines à utiliser cette connexion, puis sélectionnez OK.

Sélectionnez Enregistrer, puis, sous l’onglet Tâches , vérifiez qu’il existe trois tâches : Déployer des tables, déployer des fonctions et déployer des stratégies.
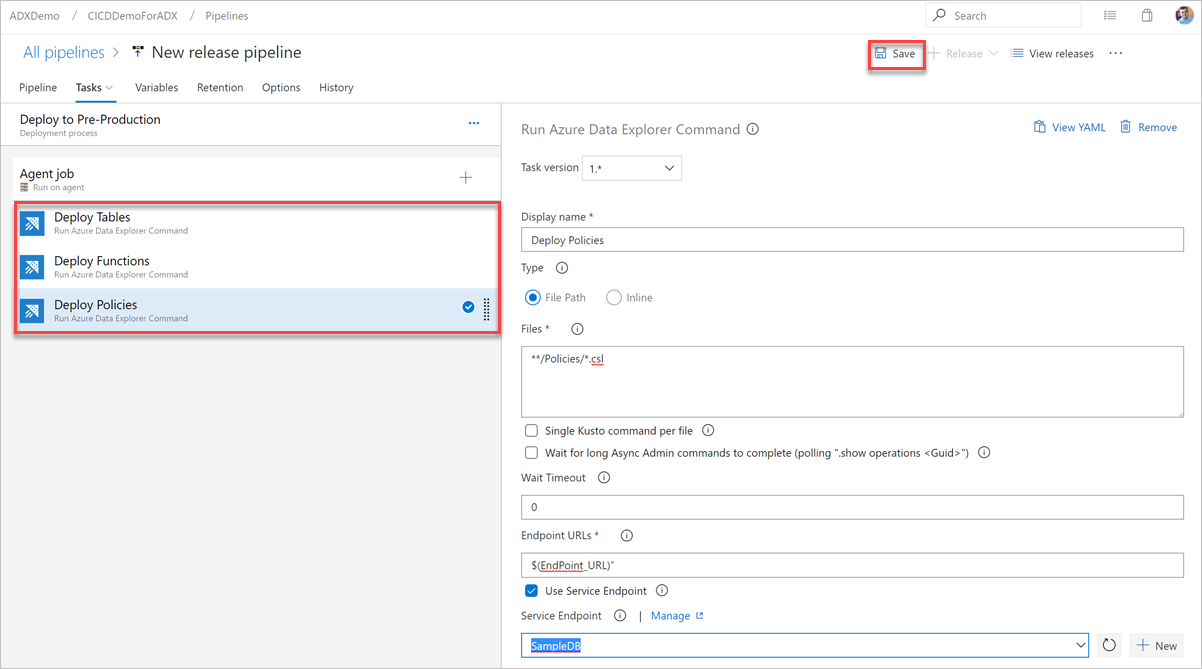
Créer une tâche de requête
Si nécessaire, créez une tâche pour exécuter une requête sur le cluster. L’exécution de requêtes dans un pipeline de build ou de mise en production peut être utilisée afin de valider un jeu de données et de faire en sorte qu’une étape réussisse ou échoue en fonction des résultats de la requête. Les critères de réussite des tâches peuvent être basés sur un seuil de nombre de lignes ou sur une valeur unique, en fonction de ce que la requête retourne.
Sous l’onglet Tâches, sélectionnez + par Travail d’agent et recherchez Azure Data Explorer.
Sous Exécuter la requête Azure Data Explorer, sélectionnez Ajouter.
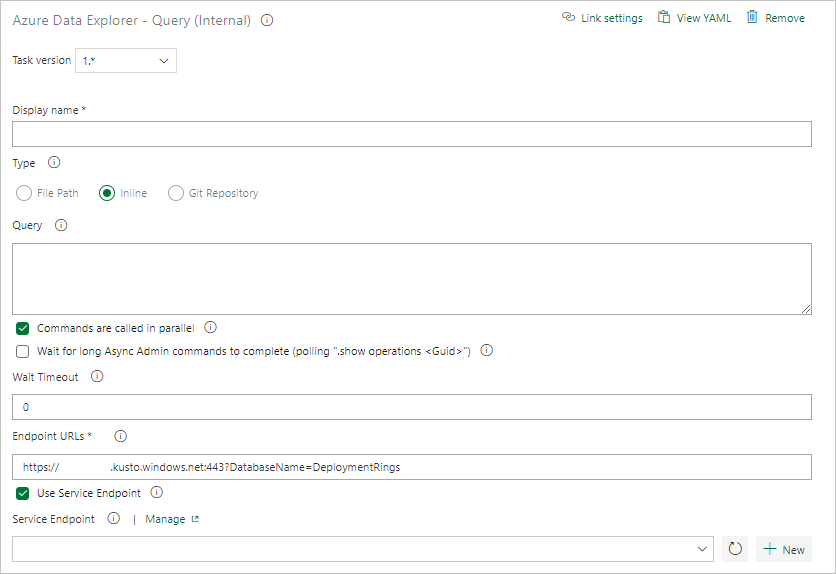
Sélectionnez Requête Kusto et mettez à jour la tâche avec les informations suivantes :
- Nom d’affichage : nom de la tâche. Par exemple, Interroger le cluster.
- Type : sélectionnez Inline.
- Requête : entrez la requête que vous souhaitez exécuter.
-
URL du point de terminaison : spécifiez la variable
EndPoint URLcréée plus tôt. - Utiliser le point de terminaison de service : sélectionnez cette option.
- Point de terminaison de service : sélectionnez un point de terminaison de service.
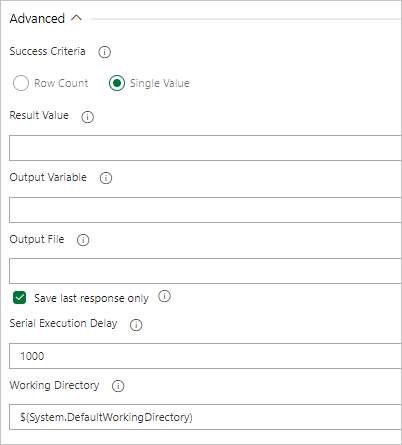
Sous Résultats de la tâche, sélectionnez les critères de réussite de la tâche en fonction des résultats de votre requête, comme suit :
Si votre requête retourne des lignes, sélectionnez Nombre de lignes et indiquez les critères requis.

Si votre requête retourne une valeur, sélectionnez Valeur unique et indiquez le résultat attendu.
Créer une tâche de porte de serveur de requête
Si nécessaire, créez une tâche pour exécuter une requête sur un cluster et contrôler la progression de la mise en production dans l’attente du nombre de lignes des résultats de la requête. La tâche de porte de serveur de requête est un travail sans agent, ce qui signifie que la requête s’exécute directement sur Azure DevOps Server.
Sous l’onglet Tâches, sélectionnez + en regard de Travail sans agent et recherchez Azure Data Explorer.
Sous Exécuter la requête Azure Data Explorer - Porte de serveur de requête, sélectionnez Ajouter.
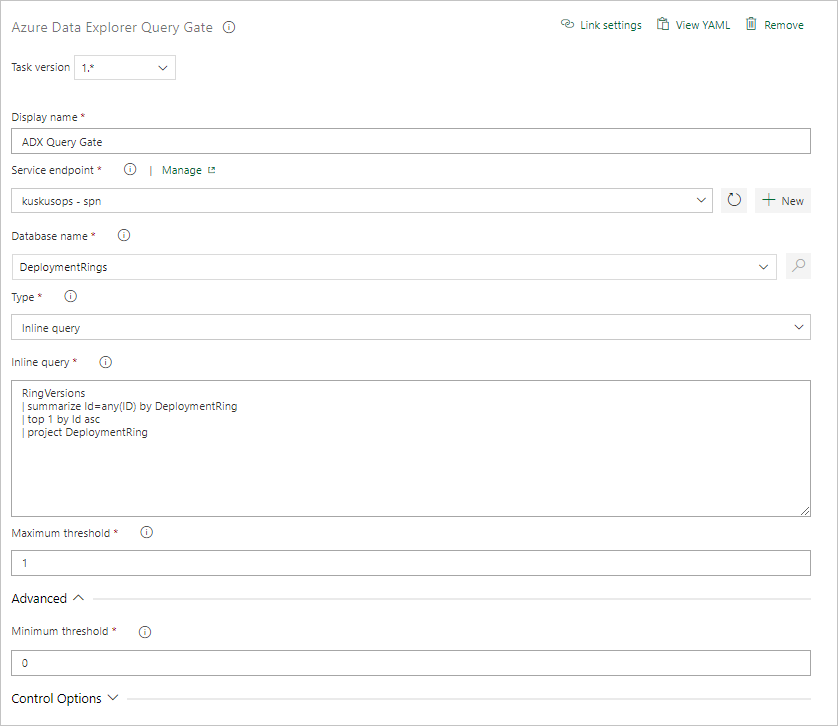
Sélectionnez Porte de serveur de requête Kusto, puis Test de porte de serveur.

Configurez la tâche en fournissant les informations suivantes :
- Nom d’affichage : nom de la porte
- Point de terminaison de service : sélectionnez un point de terminaison de service.
- Nom de la base de données : spécifiez le nom de la base de données.
- Type : sélectionnez Requête inline.
- Requête : entrez la requête que vous souhaitez exécuter.
- Seuil maximal : spécifiez le nombre maximal de lignes pour les critères de réussite de la requête.
Remarque
Vous devez voir des résultats semblables à ce qui suit lors de l’exécution de la mise en production.
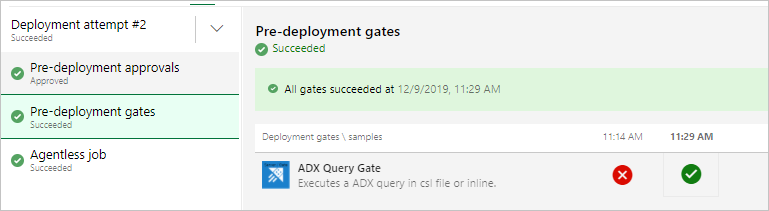
Exécuter la mise en production
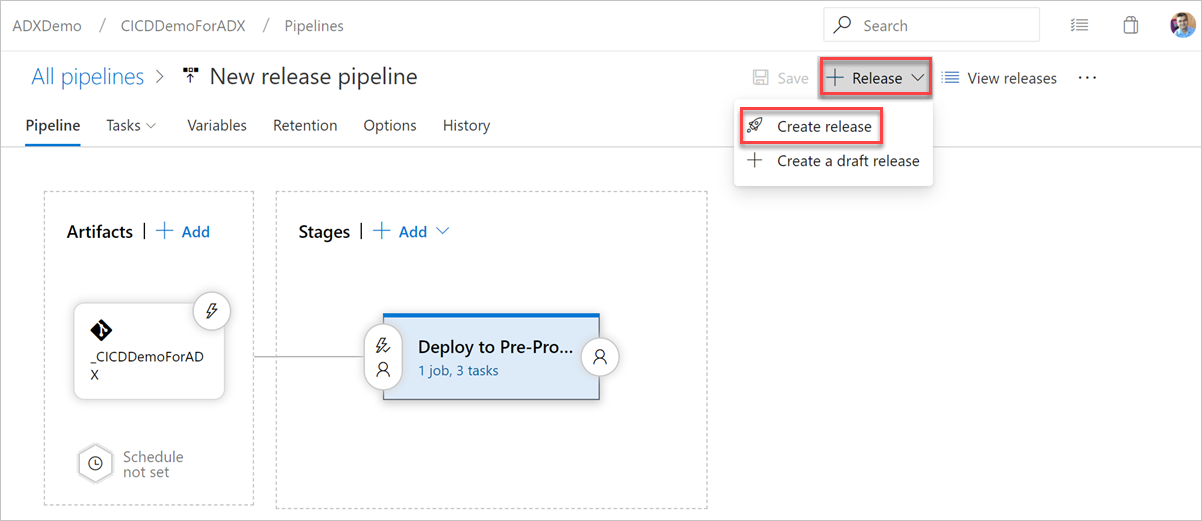
Sélectionnez + Version>Créer une version pour démarrer une version.
Dans l'onglet Journaux, vérifiez que le déploiement a réussi.
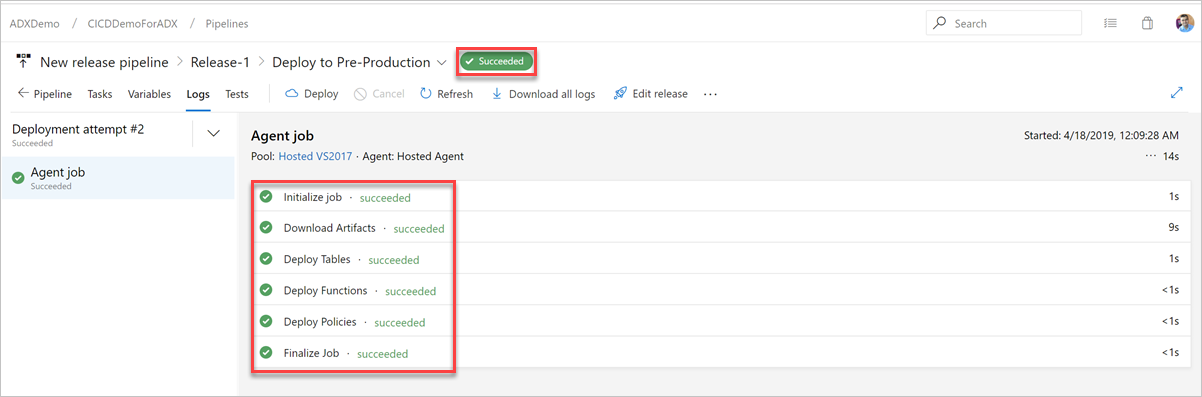
La création d’un pipeline de mise en production pour le déploiement en préproduction est à présent terminée.
Prise en charge de l’authentification sans clé pour les tâches DevOps d’Azure Data Explorer
L’extension prend en charge l’authentification sans clé pour les clusters Azure Data Explorer. L’authentification sans clé vous permet de vous authentifier auprès des clusters Azure Data Explorer sans utiliser de clé. Il est plus sécurisé et plus facile à gérer.
Utiliser les informations d’identification d’identité fédérées (FIC) dans une connexion de service Azure Data Explorer
Dans votre instance DevOps, accédez aux Paramètres du projet>Connexions de service> Nouvelle connexion de service> Azure Data Explorer.
Sélectionnez Informations d’identification d ’identité fédérées, puis entrez l’URL de votre cluster, l’ID du principal de service, l’ID de locataire, un nom de connexion de service, puis sélectionnez Enregistrer.
Dans le portail Azure, ouvrez l’application Microsoft Entra pour le principal de service spécifié.
Dans Certificats et secrets, sélectionnez informations d’identification fédérées.

Sélectionnez Ajouter des informations d’identification, puis pour le scénario d’informations d’identification fédérées, sélectionnez Autre émetteur, puis renseignez les paramètres à l’aide des informations suivantes :
Émetteur :
<https://vstoken.dev.azure.com/{System.CollectionId}>où{System.CollectionId}est l’ID de collection de votre organisation Azure DevOps. Vous trouverez l’ID de collection de la manière suivante :- Dans le pipeline de mise en production Classique Azure DevOps, sélectionnez Initialiser la tâche. L’ID de collection s’affiche dans les journaux d’activité.
Identificateur du sujet :
<sc://{DevOps_Org_name}/{Project_Name}/{Service_Connection_Name}>où{DevOps_Org_name}est le nom de l’organisation Azure DevOps,{Project_Name}est le nom du projet et{Service_Connection_Name}le nom de connexion de service que vous avez créé précédemment.Remarque
S’il y a de l’espace dans votre nom de connexion de service, vous pouvez l’utiliser avec l’espace dans le champ. Par exemple :
sc://MyOrg/MyProject/My Service Connection.Nom: entrez un nom pour les informations d’identification.
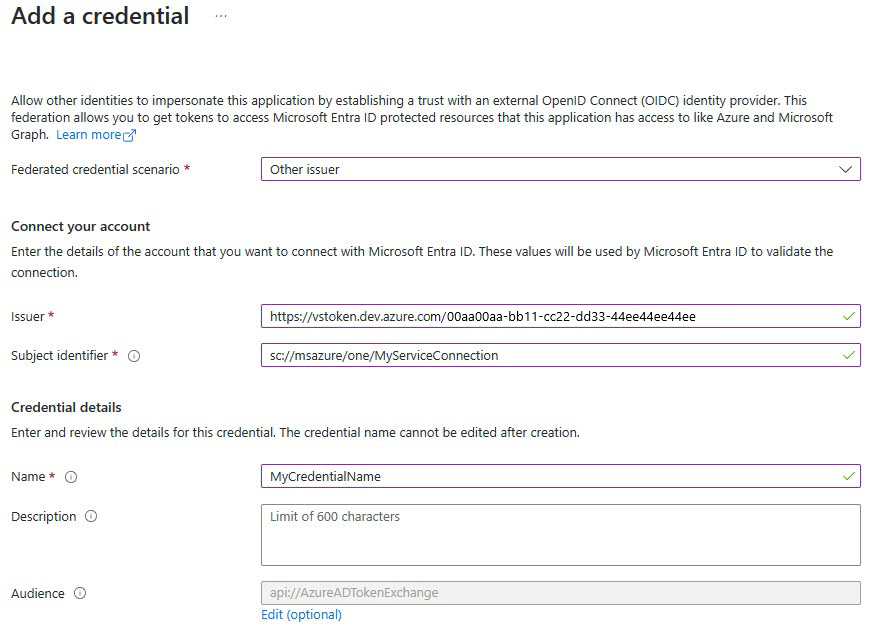
Sélectionnez Ajouter.
Utiliser des informations d’identification d’identité fédérées ou une identité managée dans une connexion de service Azure Resource Manager (ARM)
Dans votre instance DevOps, accédez aux Paramètres du projet>connexions de service> Nouveau service de connexion>Azure Resource Manager.
Sous Méthode d’authentification, sélectionnez Workload Identity Federation (automatique) pour continuer. Vous pouvez également utiliser l’option Fédération d’identité de charge de travail manuelle pour spécifier les détails de la fédération des identités de charge de travail ou l’option Identité gérée. En savoir plus sur la configuration d’une identité managée à l’aide d’Azure Resource Management dans azure Resource Manager (ARM) Service Connections.
Renseignez les détails requis, sélectionnez Vérifier, puis sélectionnez Enregistrer.
Configuration du pipeline Yaml
Vous pouvez configurer des tâches à l’aide de l’interface utilisateur web Azure DevOps ou du code YAML dans le schéma de pipeline.
Exemple de commande d'administration
steps:
- task: Azure-Kusto.PublishToADX.PublishToADX.PublishToADX@4
displayName: '<Task Name>'
inputs:
targetType: 'inline'
script: '<inline Script>'
waitForOperation: true
kustoUrls: '$(CONNECTIONSTRING):443?DatabaseName=""'
authType: 'armserviceconn'
connectedServiceARM: '<ARM Service Endpoint Name>'
serialDelay: 1000
`continueOnError: true`
condition: ne(variables['ProductVersion'], '') ## Custom condition Sample
Exemple de requête
steps:
- task: Azure-Kusto.PublishToADX.ADXQuery.ADXQuery@4
displayName: '<Task Display Name>'
inputs:
targetType: 'inline'
script: |
let badVer=
RunnersLogs | where Timestamp > ago(30m)
| where EventText startswith "$$runnerresult" and Source has "ShowDiagnostics"
| extend State = extract(@"Status='(.*)', Duration.*",1, EventText)
| where State == "Unhealthy"
| extend Reason = extract(@'"NotHealthyReason":"(.*)","IsAttentionRequired.*',1, EventText)
| extend Cluster = extract(@'Kusto.(Engine|DM|CM|ArmResourceProvider).(.*).ShowDiagnostics',2, Source)
| where Reason != "Merge success rate past 60min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%"
| where Reason != "Ingestion success rate past 5min is < 90%, Merge success rate past 60min is < 90%"
| where isnotempty(Cluster)
| summarize max(Timestamp) by Cluster,Reason
| order by max_Timestamp desc
| where Reason startswith "Differe"
| summarize by Cluster
;
DimClusters | where Cluster in (badVer)
| summarize by Cluster , CmConnectionString , ServiceConnectionString ,DeploymentRing
| extend ServiceConnectionString = strcat("#connect ", ServiceConnectionString)
| where DeploymentRing == "$(DeploymentRing)"
kustoUrls: 'https://<ClusterName>.kusto.windows.net?DatabaseName=<DatabaseName>'
authType: 'kustoserviceconn'
connectedServiceName: '<connection service name>'
minThreshold: '0'
maxThreshold: '10'
continueOnError: true